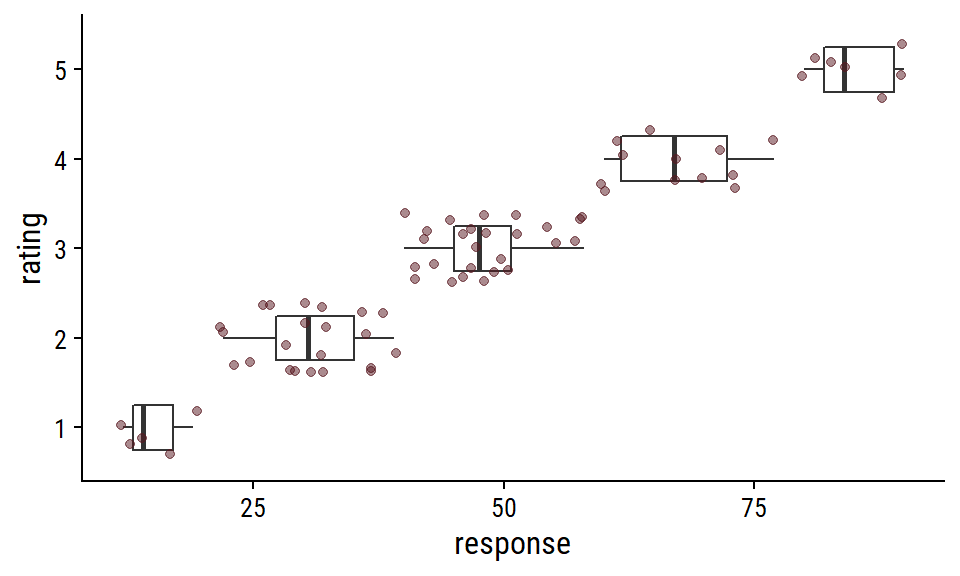
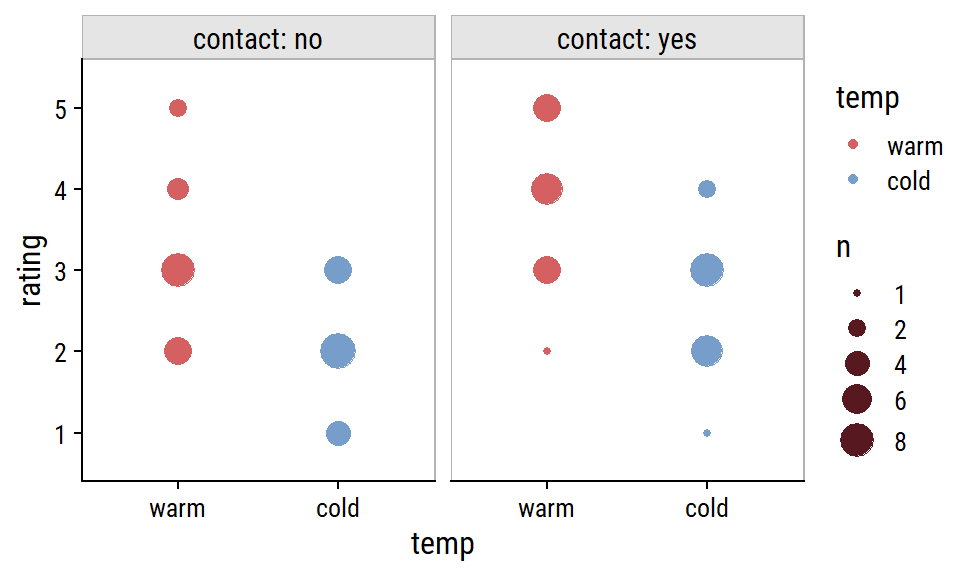
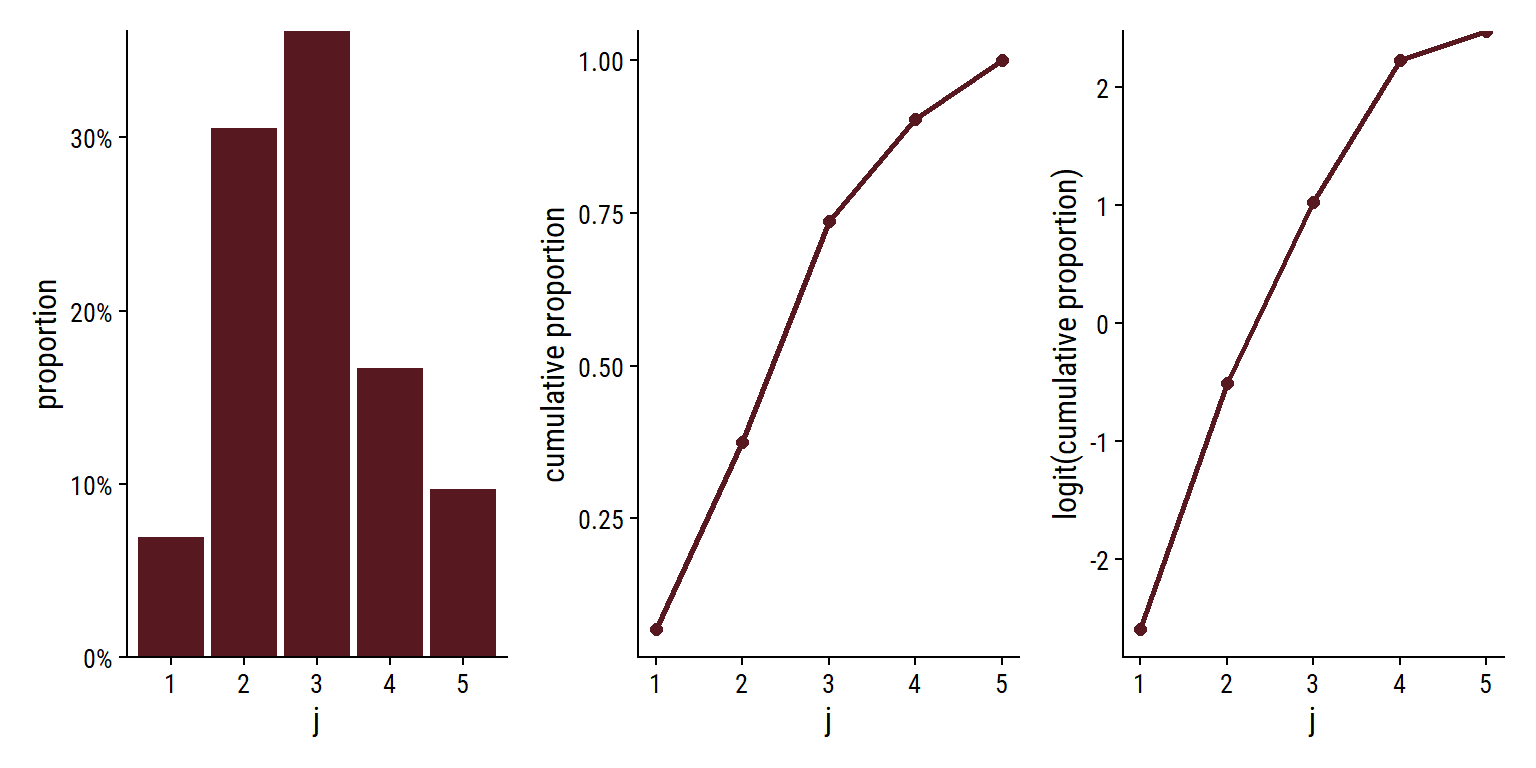
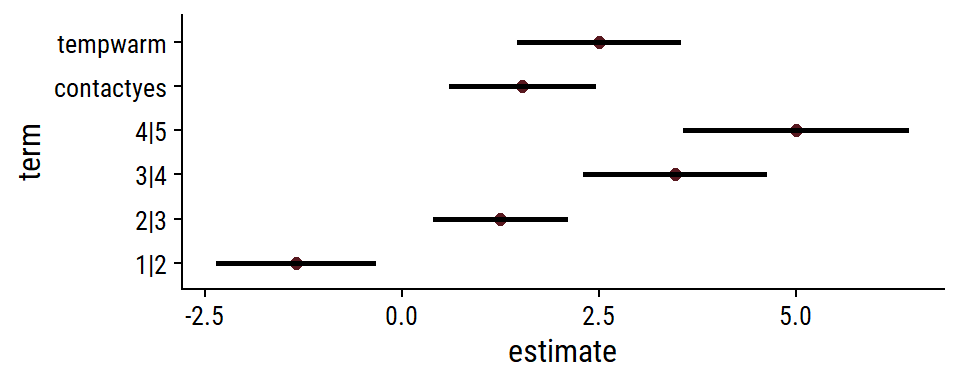
R setup
library(tidyverse)
library(dunnr)
library(gt)
library(broom)
library(patchwork)
extrafont::loadfonts(device = "win", quiet = TRUE)
theme_set(theme_td())
set_geom_fonts()
set_palette()
wine_red <- "#58181F"
update_geom_defaults("point", list(color = wine_red))
update_geom_defaults("line", list(color = wine_red))