Though I won’t be reproducing their examples, Bürkner and Vuorre (2019) give a great tutorial of using brms for ordinal regression models. It also frames the cumulative model in the terms of a latent (not observable) continuous variable \(\tilde{y}\), which has been categorized into the observed ordinal variable \(y\). I found this way of thinking very intuitive, and it helped make a lot of the concepts click.
This post also serves as practice in Bayesian inference, so I’ll be comparing the results here to those from part 1, and explore different choices of prior distributions.
Setup
Load brms, tidybayes and the wine data from Randall (1989) that was analyzed in part 1.
library(brms)library(tidybayes)# Detect and set the number of cores for MCMCoptions(mc.cores = parallel::detectCores())library(ordinal)data(wine)wine <-as_tibble(wine)
Fitting the models
I will be fitting these models of wine bitterness ratings:
where \(p(y_i \leq j)\) is the probability of a rating less than or equal to \(j\), \(\theta_j\) are the thresholds for the \(J-1 = 4\) levels, \(u(\text{judge}_i)\) are judge-specific random effects, and \(\beta_1\) and \(\beta_2\) are fixed effect coefficients for \(\text{temp}_i\) and \(\text{contact}_i\). (see part 1 for more details).
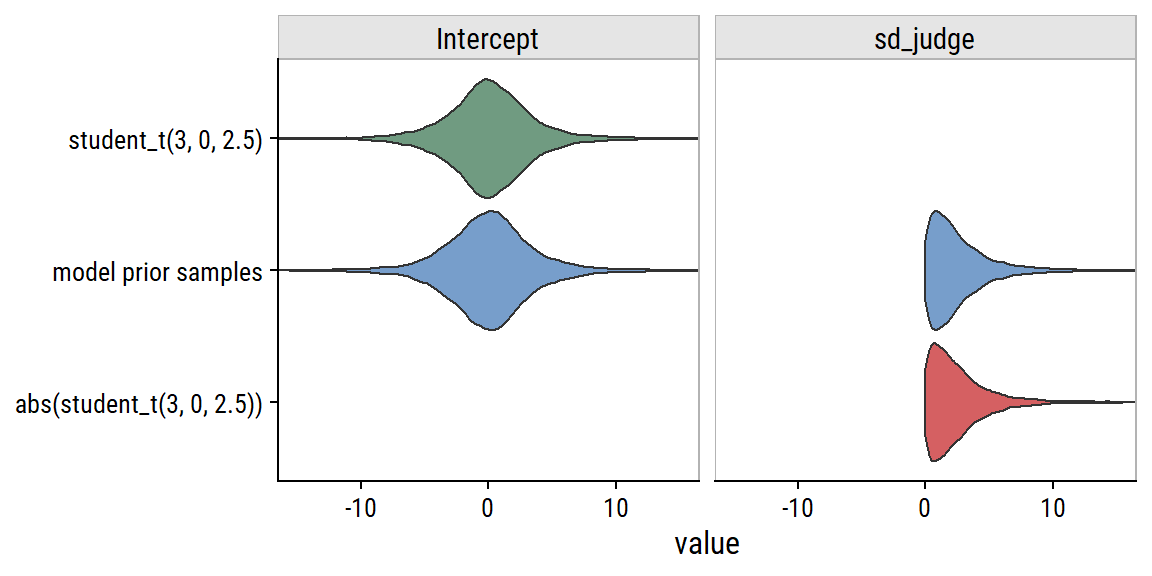
Any prior values outside of this range would essentially zero cumulative probability for a level \(\leq j\).
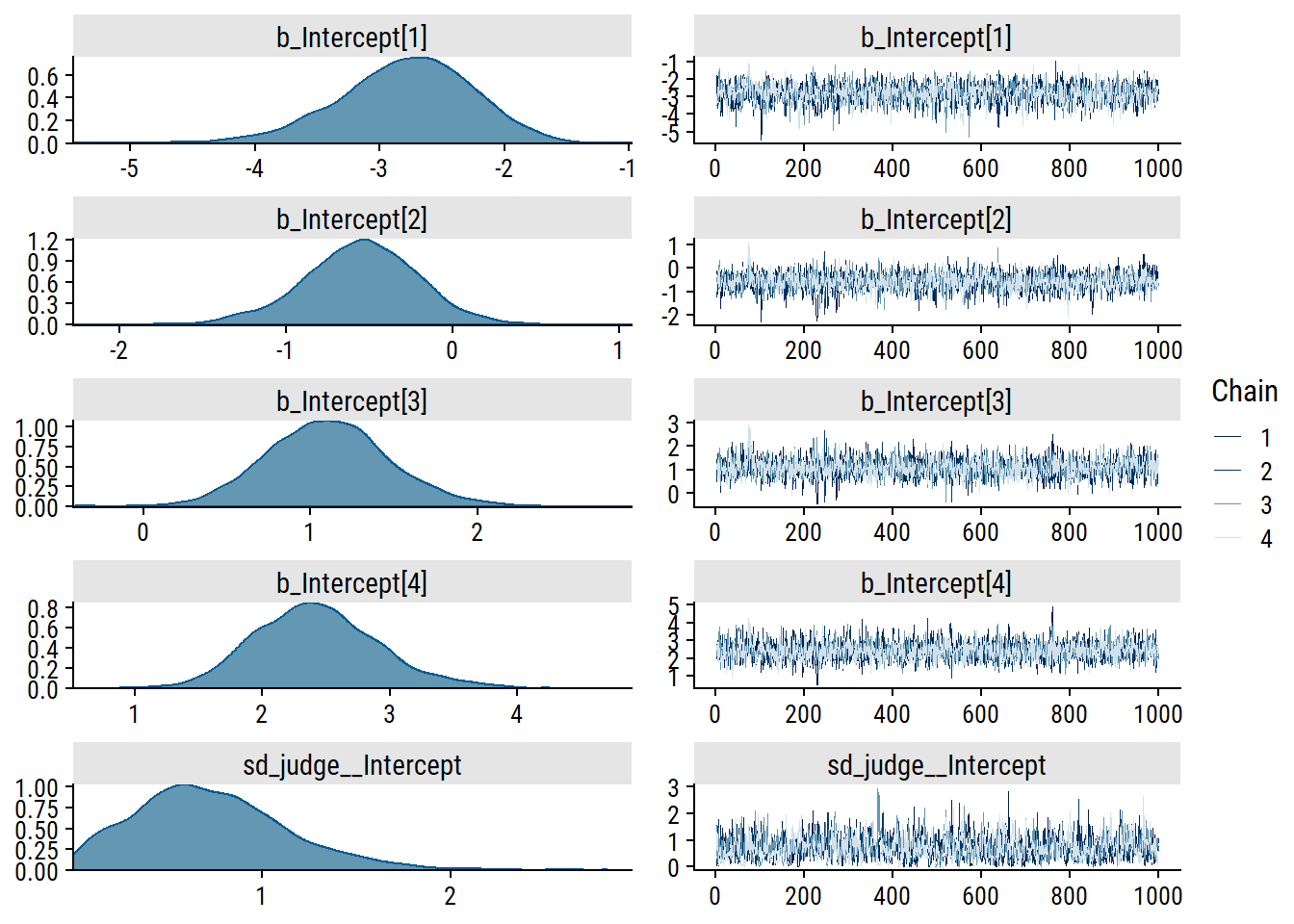
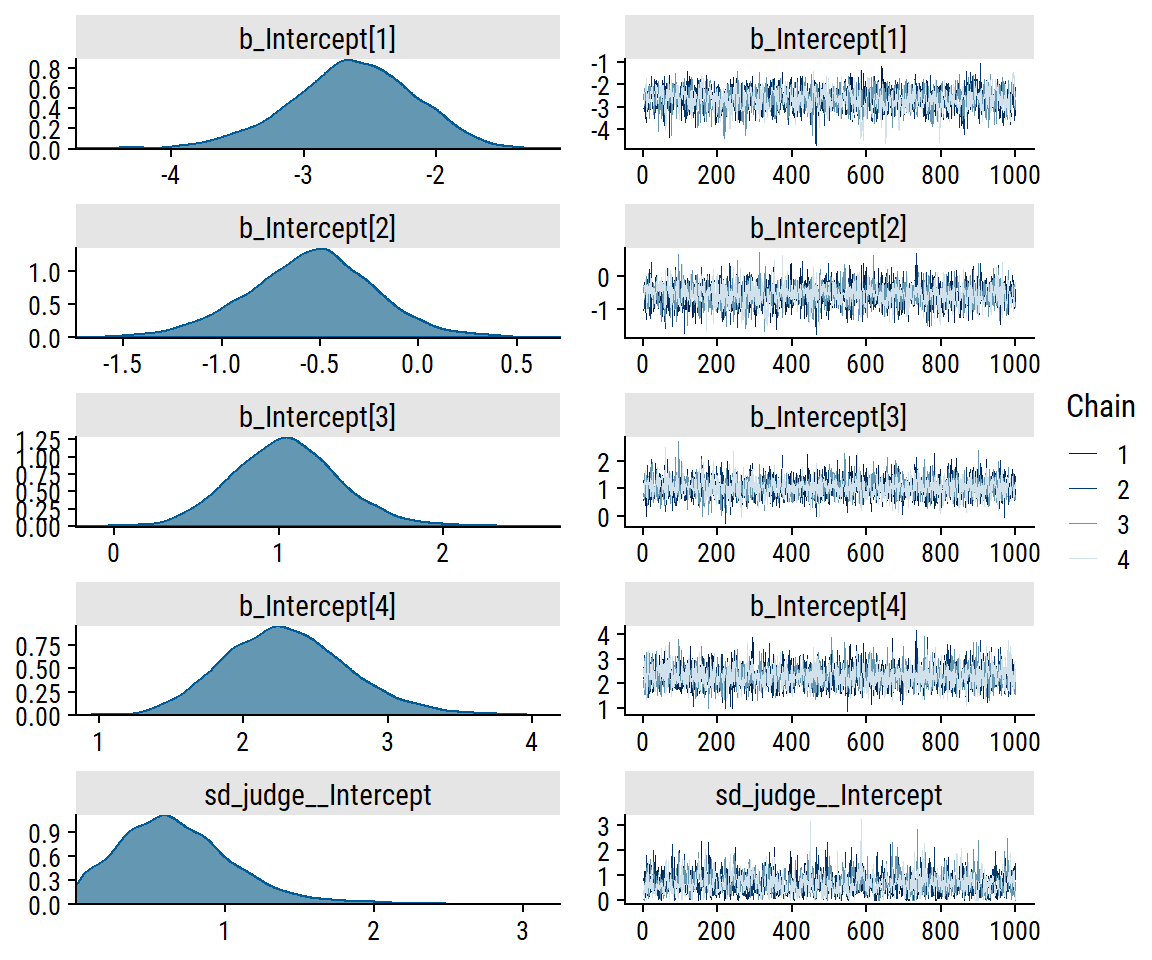
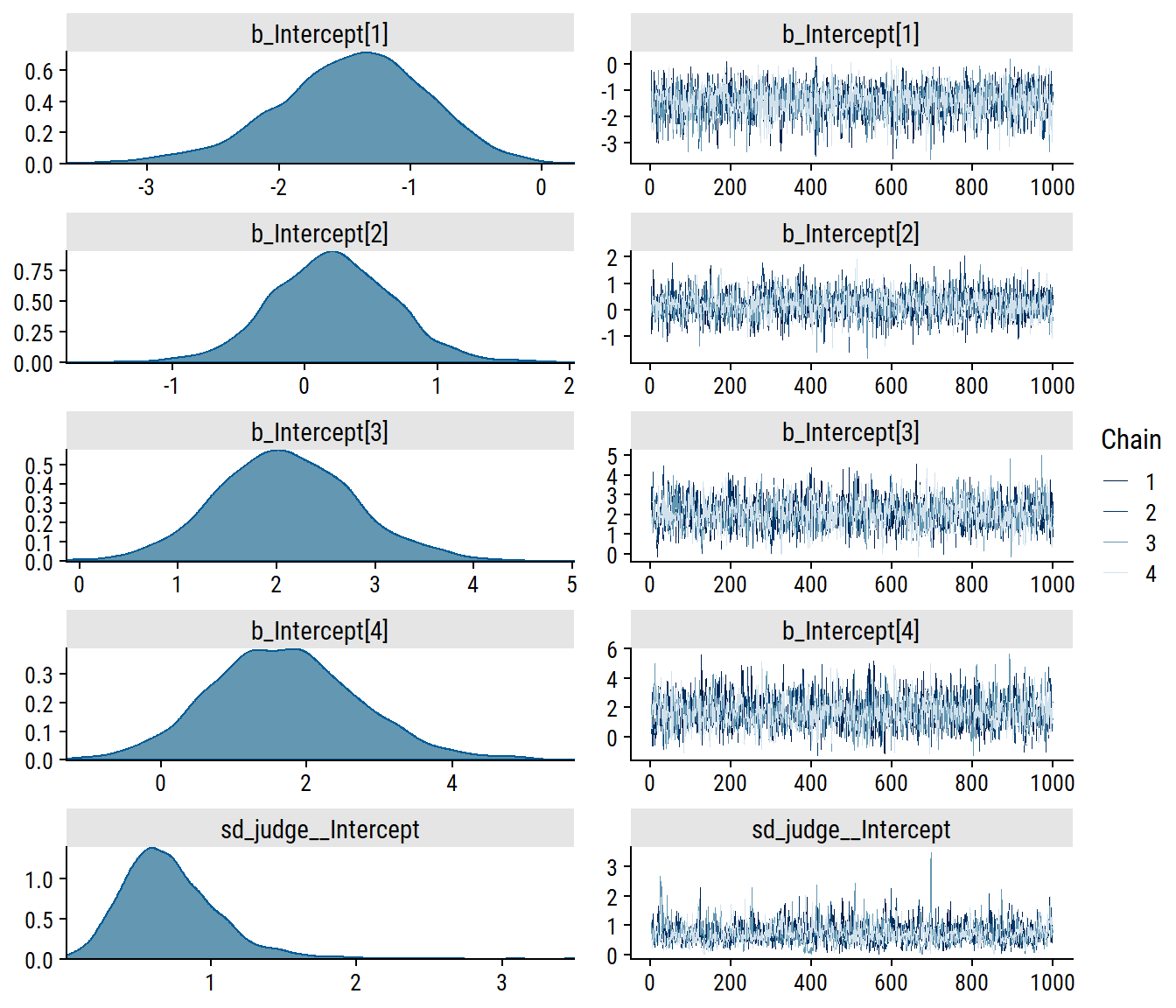
Now that we’ve thought about our (default) prior assumptions, investigate the chains:
plot(brm_rating_null, ask =FALSE,# Only plot specified variablesvariable ="^b_|^sd_", regex =TRUE)
The intercept trace plots look good to me. There are some spikes in sd_judge__Intercept, but not enough to be concerning.
Print the model estimates:
brm_rating_null
Family: cumulative
Links: mu = logit; disc = identity
Formula: rating ~ 1 + (1 | judge)
Data: wine (Number of observations: 72)
Draws: 4 chains, each with iter = 2000; warmup = 1000; thin = 1;
total post-warmup draws = 4000
Group-Level Effects:
~judge (Number of levels: 9)
Estimate Est.Error l-95% CI u-95% CI Rhat Bulk_ESS Tail_ESS
sd(Intercept) 0.73 0.41 0.07 1.64 1.00 1339 1614
Population-Level Effects:
Estimate Est.Error l-95% CI u-95% CI Rhat Bulk_ESS Tail_ESS
Intercept[1] -2.79 0.54 -3.93 -1.81 1.00 2240 2206
Intercept[2] -0.56 0.36 -1.30 0.12 1.00 2777 2750
Intercept[3] 1.10 0.38 0.39 1.87 1.00 2986 2927
Intercept[4] 2.42 0.49 1.54 3.47 1.00 3761 2958
Family Specific Parameters:
Estimate Est.Error l-95% CI u-95% CI Rhat Bulk_ESS Tail_ESS
disc 1.00 0.00 1.00 1.00 NA NA NA
Draws were sampled using sampling(NUTS). For each parameter, Bulk_ESS
and Tail_ESS are effective sample size measures, and Rhat is the potential
scale reduction factor on split chains (at convergence, Rhat = 1).
The Rhat values are also a good sign of model convergence.
Compare the null Bayesian model estimates to the frequentist estimates:
# Can't figure out how to extract random effect SDs from a clmm model, use clmm2clmm2_rating_null <-clmm2( rating ~1, random = judge,data = wine, link ="logistic", Hess =TRUE )# Unfortunately, clmm2 doesn't have a broom::tidy() functionsummary(clmm2_rating_null) %>%coef() %>%as_tibble() %>%mutate(term =str_c("b_Intercept[", 1:4, "]")) %>%bind_rows(tibble(Estimate =as.numeric(clmm2_rating_null$stDev),term ="sd_judge__Intercept" ) ) %>% janitor::clean_names() %>%left_join( broom.mixed::tidyMCMC(brm_rating_null, conf.int =TRUE),by ="term" ) %>%relocate(term) %>%mutate(pr_z = scales::pvalue(pr_z),across(where(is.numeric), ~round(., 2)) ) %>%gt() %>%tab_spanner(label ="ordinal::clmm",columns =c(estimate.x, std_error, z_value, pr_z) ) %>%tab_spanner(label ="brms::brm",columns =c(estimate.y, std.error, conf.low, conf.high) ) %>%sub_missing(columns =everything(), missing_text ="")
term
ordinal::clmm
brms::brm
estimate.x
std_error
z_value
pr_z
estimate.y
std.error
conf.low
conf.high
b_Intercept[1]
-2.72
0.52
-5.25
<0.001
-2.76
0.54
-3.93
-1.81
b_Intercept[2]
-0.54
0.32
-1.72
0.085
-0.55
0.36
-1.30
0.12
b_Intercept[3]
1.10
0.34
3.24
0.001
1.10
0.38
0.39
1.87
b_Intercept[4]
2.35
0.46
5.13
<0.001
2.40
0.49
1.54
3.47
sd_judge__Intercept
0.57
0.69
0.41
0.07
1.64
Frequentist estimates are pretty close to the Bayesian estimates with naive priors.
Choice of priors
So what are reasonable priors for this data and model? My go-to resource for this kind of thing is this page from the stan wiki, but under the “Prior for cutpoints in ordered logit or probit regression”, they have a couple suggestions like “uniform priors typically should be ok”, but also say “Need to flesh out this section with examples”, so not a lot of help there.
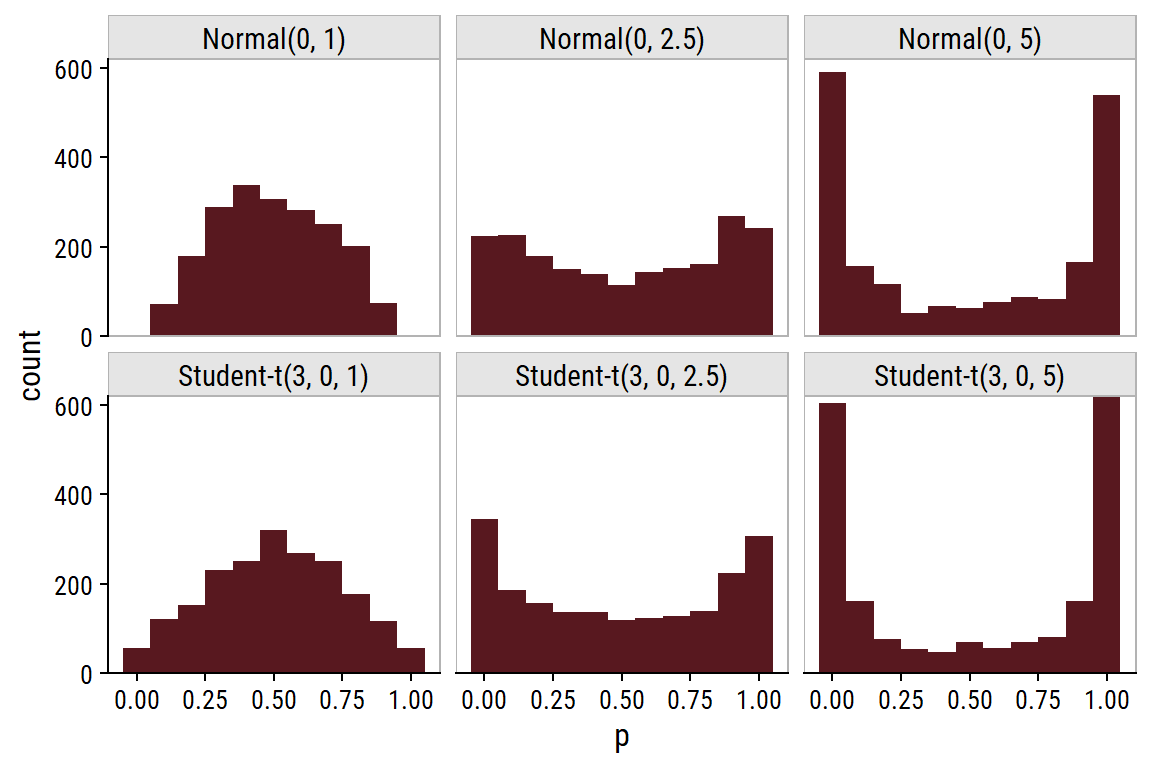
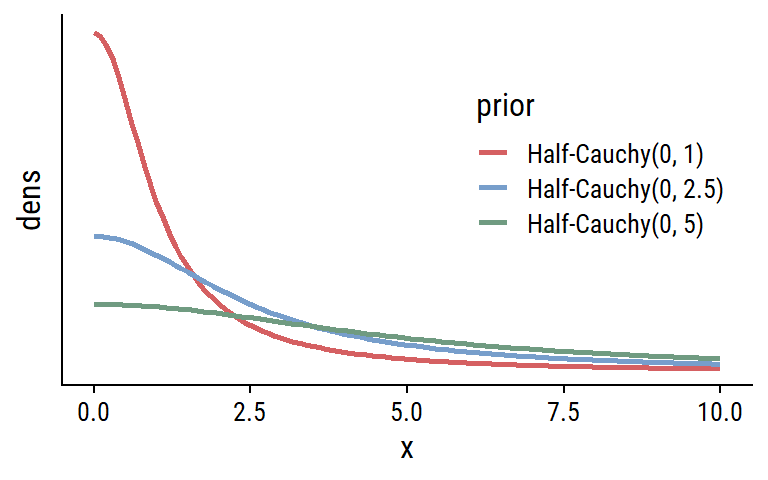
I’ll consider the following priors on the the thresholds:
The \(\text{Normal}(0, 5)\) and \(\text{Student-}t(3, 0, 5)\) priors place most of the samples at the extremes (cumulative probabilities of 0 and 100%). The \(\text{Normal}(0, 2.5)\) and \(\text{Student-}t(3, 0, 2.5)\) are sensible default priors because they are fairly uniform in the probability space, although they do have slight peaks at the extremes. The \(\text{Normal}(0, 1)\) and \(\text{Student-}t(3, 0, 1)\) prior distributions are bell-shaped around \(p = 0.5\), and might be appropriate if we have reason to believe that there will be no extreme probabilities.
As expected, these priors don’t noticeably improve the model convergence (which was already good). Likewise, the model estimates changed only slightly:
get_prior(f_rating_contact_temp, data = wine, family =cumulative("logit")) %>%gt()
prior
class
coef
group
resp
dpar
nlpar
lb
ub
source
b
default
b
contactyes
default
b
tempwarm
default
student_t(3, 0, 2.5)
Intercept
default
Intercept
1
default
Intercept
2
default
Intercept
3
default
Intercept
4
default
student_t(3, 0, 2.5)
sd
0
default
sd
judge
default
sd
Intercept
judge
default
We know from part 1 that contactyes (\(\beta_1\)) and tempwarm (\(\beta_2\)) are associated with higher ratings, but we shouldn’t be biasing our priors by using the same data we are modeling. Instead, use a weakly regularizing normal distributions centered at 0:
The estimates from the Bayesian regression with default priors are very close to the frequentist estimates.
But is the model actually a better fit to the data? We can compare them with leave-one-out cross-validation (LOOCV) based on the posterior likelihoods:
Output of model 'brm_rating_contact_temp':
Computed from 4000 by 72 log-likelihood matrix
Estimate SE
elpd_loo -85.2 4.3
p_loo 10.3 0.9
looic 170.4 8.5
------
Monte Carlo SE of elpd_loo is 0.1.
All Pareto k estimates are good (k < 0.5).
See help('pareto-k-diagnostic') for details.
Output of model 'brm_rating_contact_temp_default_prior':
Computed from 4000 by 72 log-likelihood matrix
Estimate SE
elpd_loo -85.3 5.3
p_loo 12.7 1.3
looic 170.5 10.6
------
Monte Carlo SE of elpd_loo is 0.1.
All Pareto k estimates are good (k < 0.5).
See help('pareto-k-diagnostic') for details.
Model comparisons:
elpd_diff se_diff
brm_rating_contact_temp 0.0 0.0
brm_rating_contact_temp_default_prior -0.1 1.1
The output here is the expected log predicted density (elpd_loo), the estimated number of effective parameters (p_loo), and the LOOCV information criteria (looic). Lower values of looic indicate better model fit. These are essentially equal, so the weak priors have not made a large difference to the model fit, as seen in the low elpd_diff relative to se_diff.
Aside: adjacent-category models
Here are what Bürkner and Vuorre (2019) had to say about the adjacent-category class of ordinal models.
Predicts the decision between two adjacent categories \(k\) and \(k+1\).
Latent variables \(\tilde{Y}_k\) with thresholds \(\tau_k\) and cumulative distribution function \(F\).
If \(\tilde{Y}_k < \tau_k\), we choose category \(k\); \(k+1\) otherwise.
It is difficult to think of a natural process leading to them; chosen for its mathematical convenience rather than quality of interpretation.
Mathematically:
\[
\text{Pr}(Y = k | Y \in \{k, k+1\}) = F(\tau_k).
\]
Suppose the latent variable \(\tilde{Y}_2\) is standard normally distributed with distribution function \(\Phi\), and \(\tau_2\) = 1. Then the probability of choosing \(Y\) = 2 over \(Y\) = 3 would be written as:
In all of the models specified so far, all fixed effects were presumed to affect all response categories equally. For example, the effect of temp = warm had a mean effect of \(\beta_1\) = 2.67 on the thresholds \(\theta_j\), for all \(j = 1, 2, 3, 4\).
This may not be an appropriate assumption. For example, temp warm might have little relation to the highest rating, but it may strongly predict ratings of 3 relative to 1 or 2.
If this is a possibility, then we can model the predictor as having a category-specific effect by estimating \(K-1\) coefficients for it. The reason we’ve introduced the adjacent-category model is that it is straightforward to incorporate these effects (sequential models work as well). Cumulative models, however, can lead to negative probabilities, and so should be avoided when using category-specific effects.
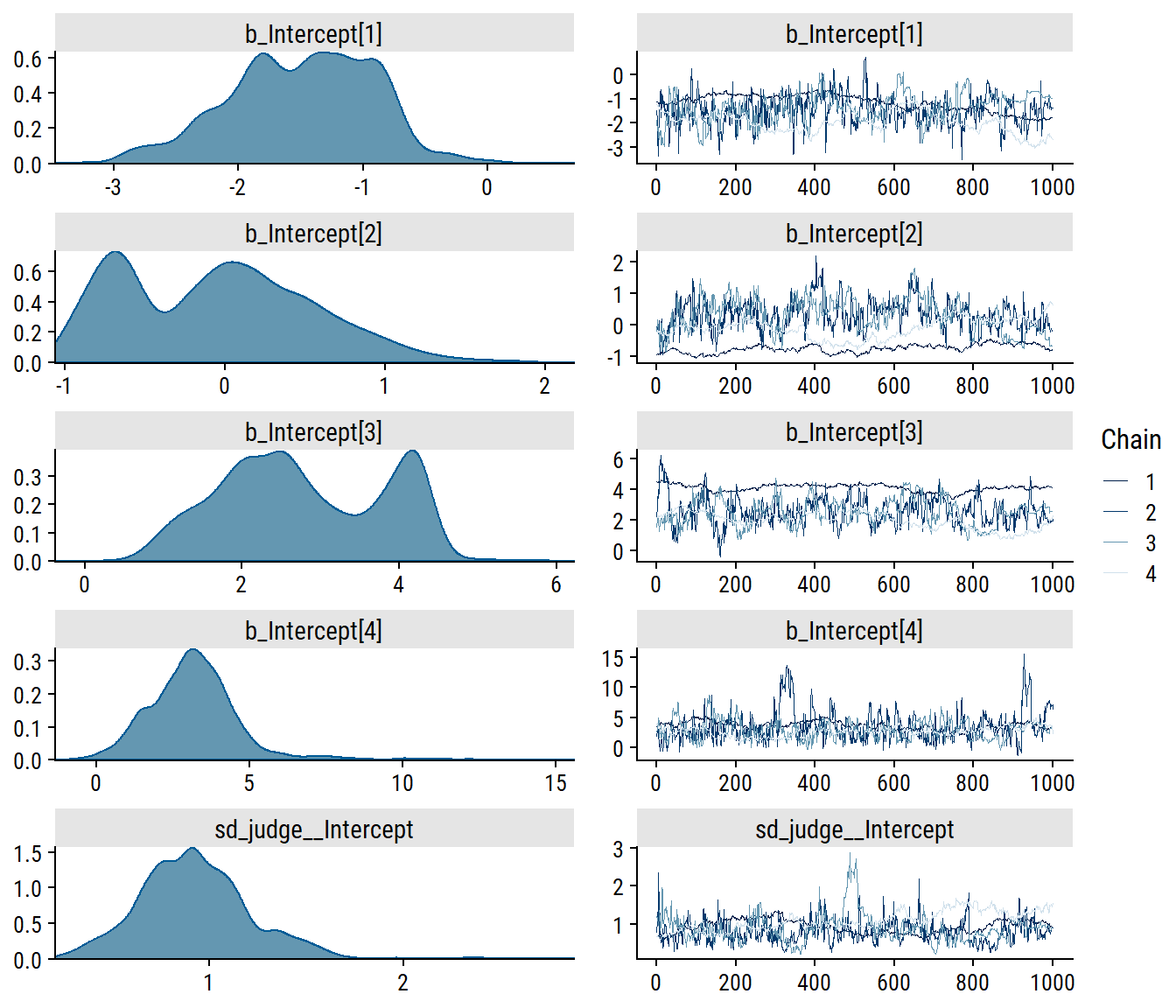
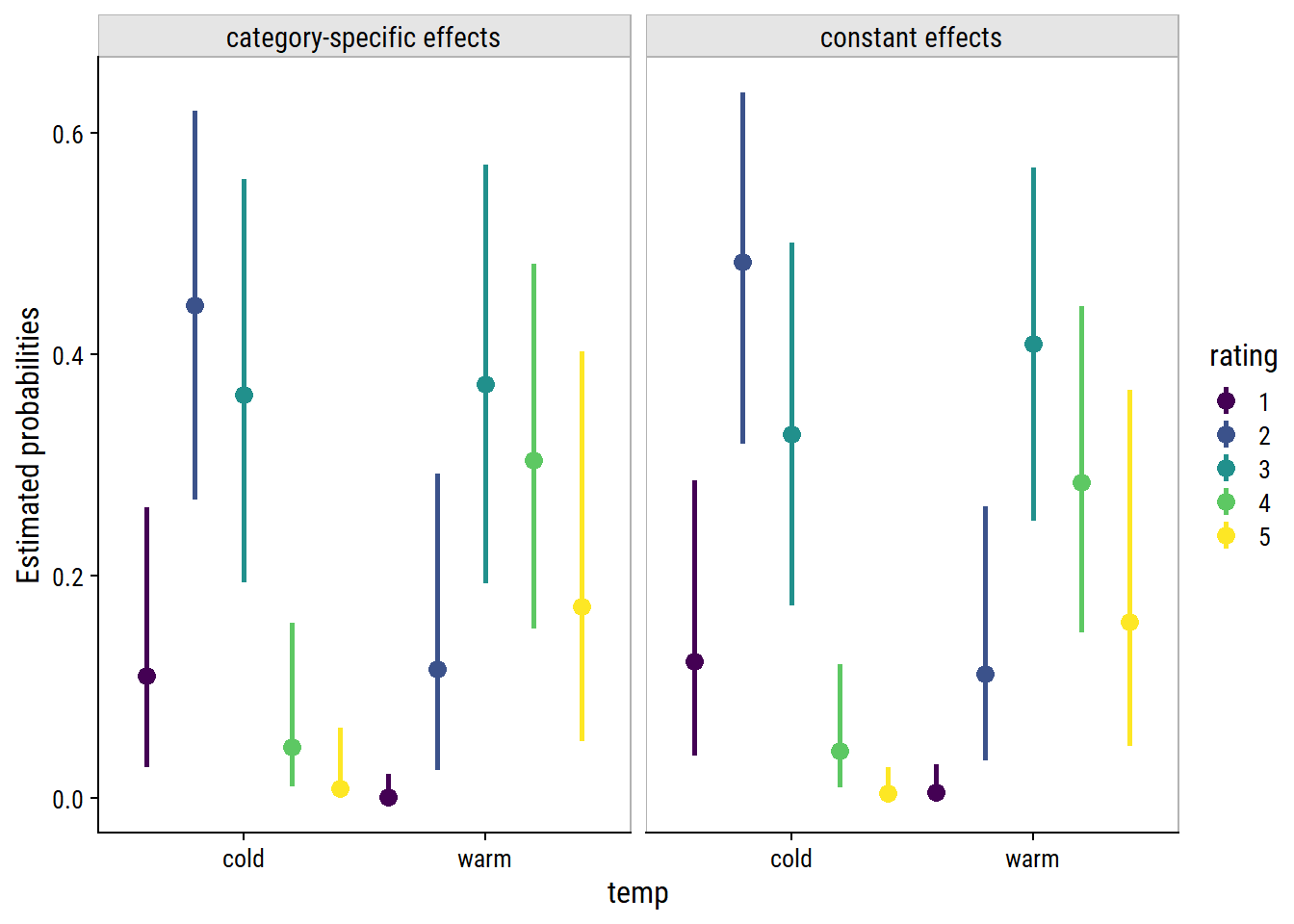
Fit the adjacent-category model with category-specific effects on temp:
Most of the divergence is coming from estimating the lowest coefficient \(\beta_{11}\) (bcs_tempwarm[1]). I will try some regularizing priors (previously defined) and increasing the adapt_delta argument:
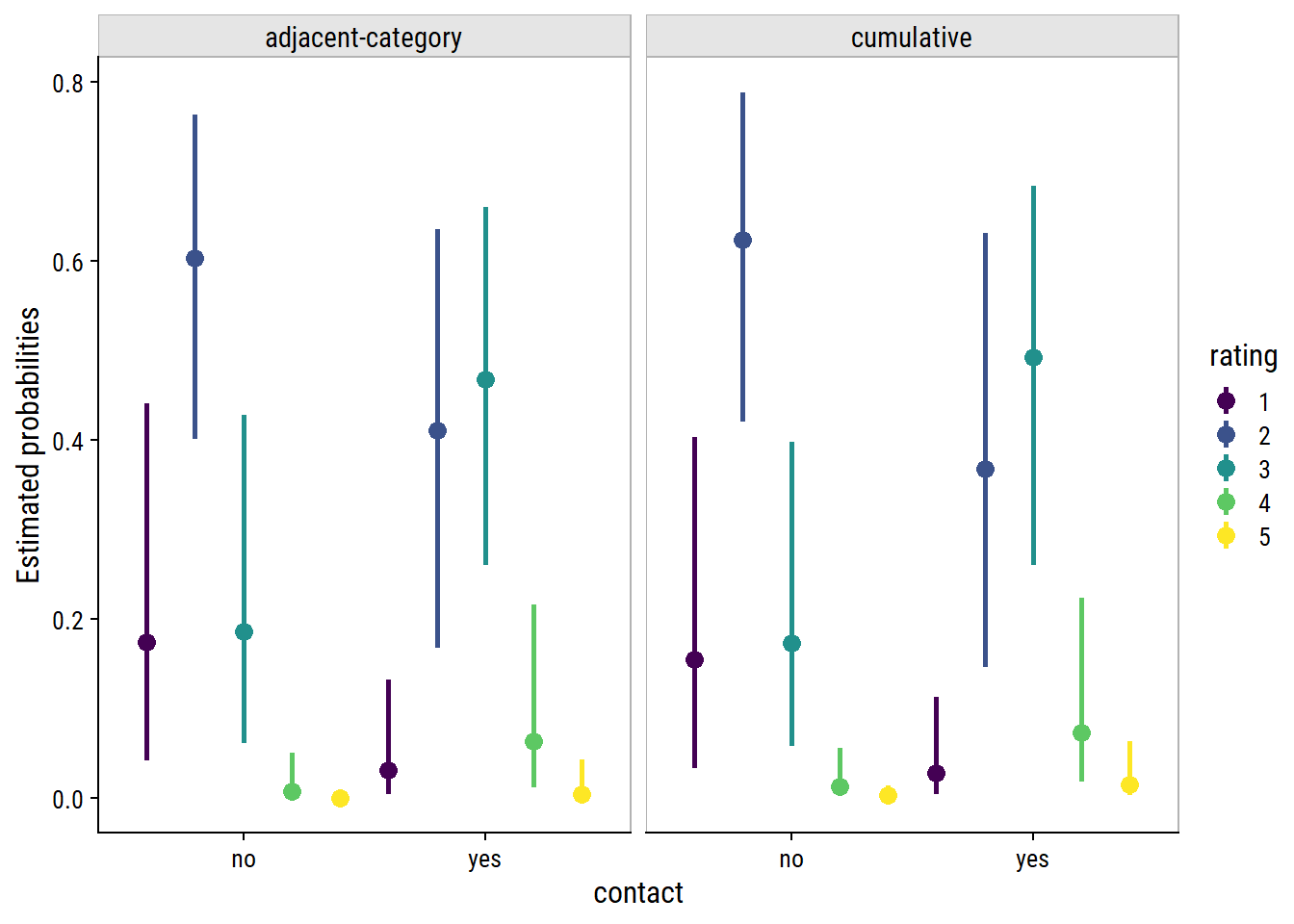
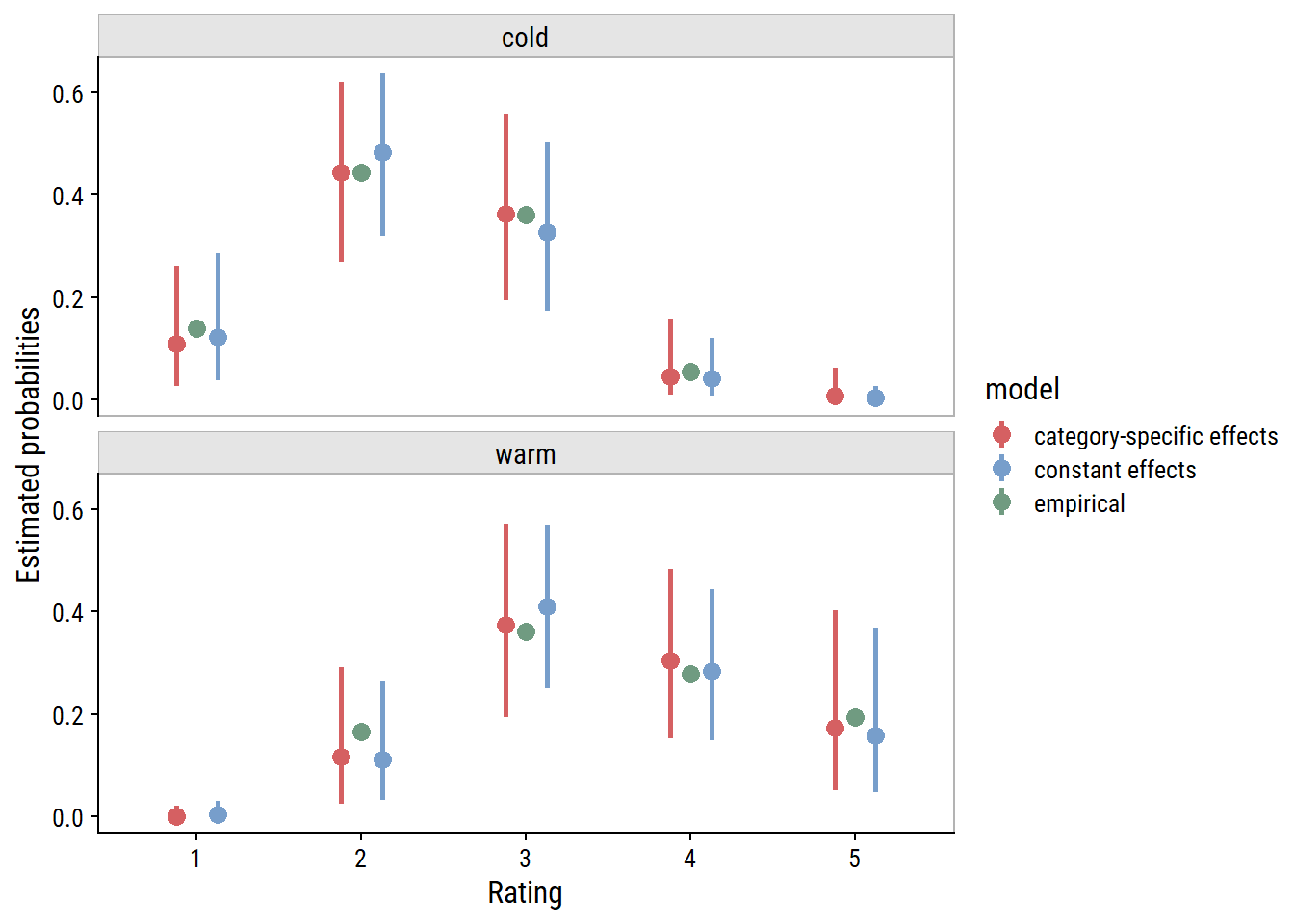
Or, put the probabilities for each model side-by-side, along with the empirical probabilities:
ce_rating_temp_weak_prior_acat$`temp:cats__`%>%mutate(model ="constant effects") %>%bind_rows( ce_rating_cs_temp_weak_prior_acat$`temp:cats__`%>%mutate(model ="category-specific effects") ) %>%ggplot(aes(x = effect2__, y = estimate__, color = model)) +geom_point(position =position_dodge(0.5), size =3) +geom_linerange(aes(ymin = lower__, ymax = upper__),position =position_dodge(0.5), size =1) +geom_point(data = wine %>%group_by(temp, rating) %>%tally() %>%group_by(temp) %>%mutate(p = n /sum(n), model ="empirical"),aes(x = rating, y = p, color = model), size =3 ) +facet_wrap(~temp, ncol =1) +labs(y ="Estimated probabilities", x ="Rating", color ="model") + dunnr::add_facet_borders()
The category-specific effects have not made a notable difference to the estimated probabilities. The constant effects model may even be better, meaning that it is a valid assumption for these data, and category-specific effects are excessive.
Conclusion
The brms package is a great tool for fitting Bayesian models in Stan. Though it requires a more thoughtful approach (what are my priors?) and longer computations (Markov chain Monte Carlo can be slow), I find Bayesian inference far more intuitive than frequentist null hypothesis significance testing.
For instance, consider the cumulative link regression with contact and temp:
With the Bayesian model, not only do we have the full posterior to work with, we can make conclusions like:
Under weakly regularizing priors, temperature probably affects wine rating \(\beta_{\text{temp}}\) = 2.67, 95% credible interval = 1.72, 3.71.
Versus the frequentist model:
There is evidence against the null hypothesis that \(\beta_{\text{temp}}\) = 0, \(p\) < 0.001. The point estimate from the model was 3.06, 95% confidence interval = 1.9, 4.23.
With frequentist inference, we find the probability of the data assuming the null hypothesis is true, \(P(\text{data}|H_0)\). With Bayesian inference, we find the probability of a hypothesis given the data, \(P(H|\text{data})\), which means we don’t even have to consider the “null world.” Much more intuitive, in my opinion.
Reproducibility
Session info
setting value
version R version 4.2.1 (2022-06-23 ucrt)
os Windows 10 x64 (build 19044)
system x86_64, mingw32
ui RTerm
language (EN)
collate English_Canada.utf8
ctype English_Canada.utf8
tz America/Curacao
date 2022-10-27
pandoc 2.18 @ C:/Program Files/RStudio/bin/quarto/bin/tools/ (via rmarkdown)
Git repository
Local: main C:/Users/tdunn/Documents/tdunn-quarto
Remote: main @ origin (https://github.com/taylordunn/tdunn-quarto.git)
Head: [4eb5bf2] 2022-10-26: Added font import to style sheet
Bürkner, Paul-Christian, and Matti Vuorre. 2019. “Ordinal Regression Models in Psychology: A Tutorial.”Advances in Methods and Practices in Psychological Science 2 (1): 77–101. https://doi.org/10.1177/2515245918823199.
Randall, J. H. 1989. “The Analysis of Sensory Data by Generalized Linear Model.”Biometrical Journal 31 (7): 781–93. https://doi.org/10.1002/bimj.4710310703.