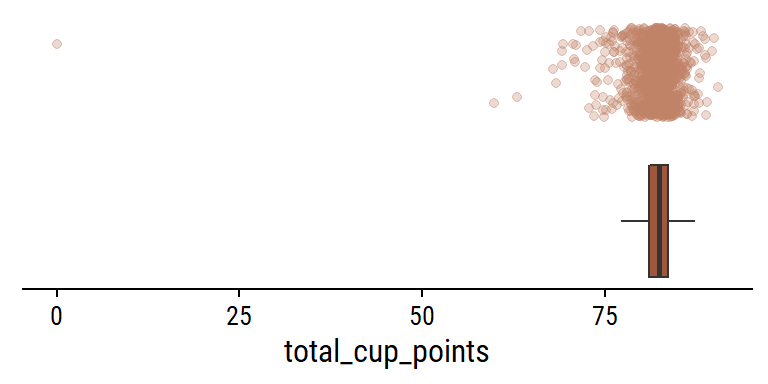
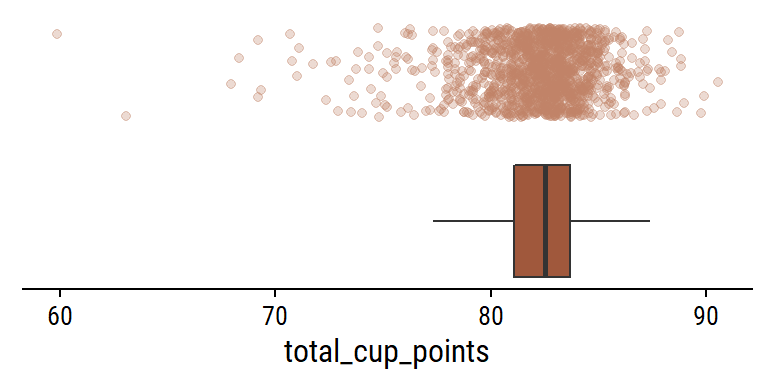
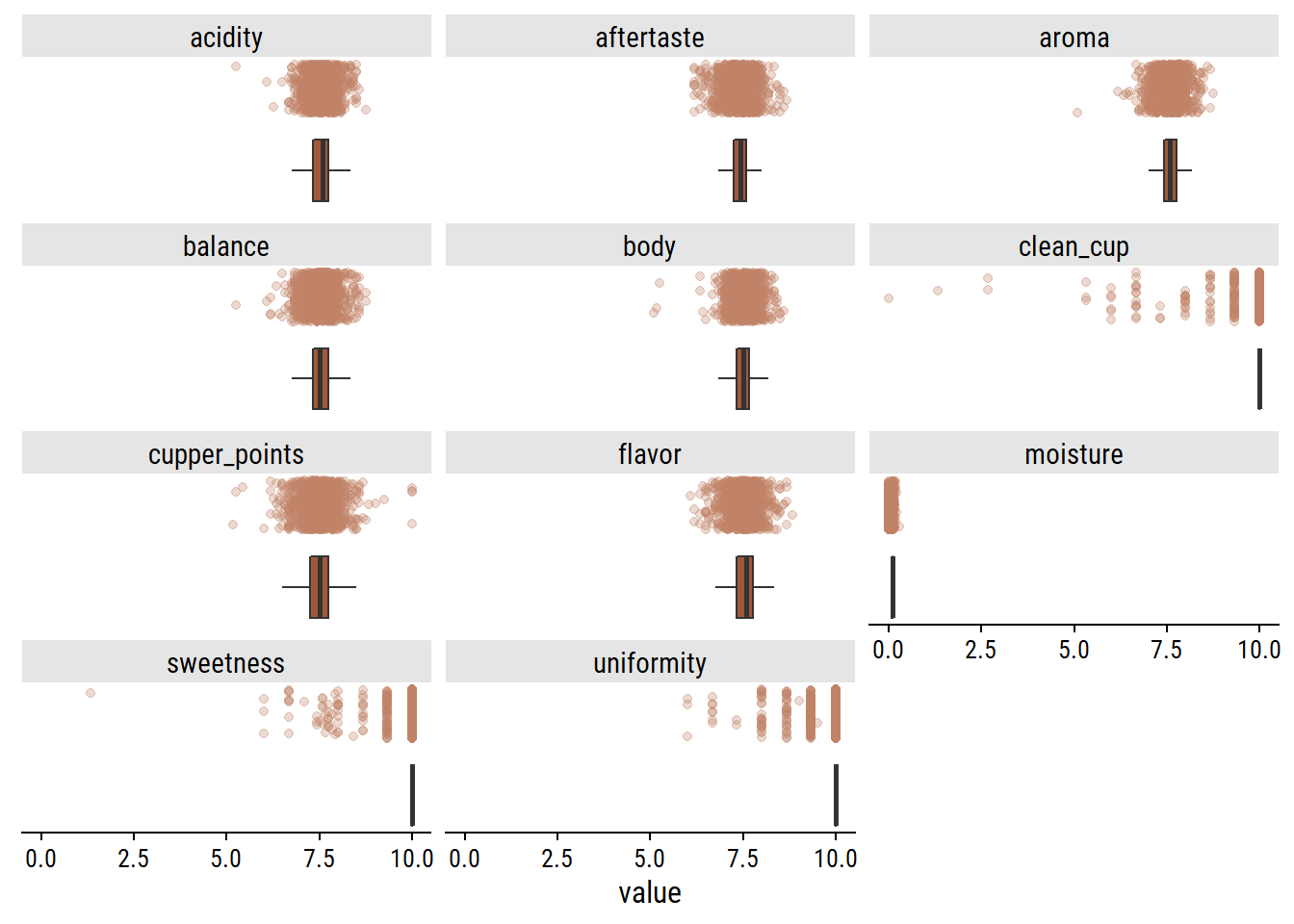
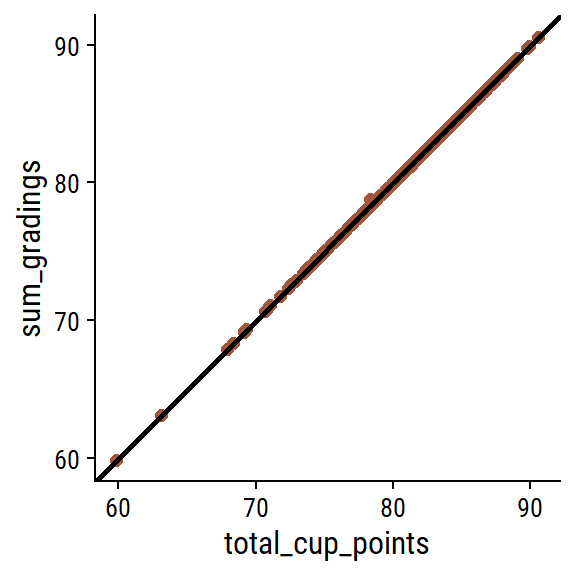
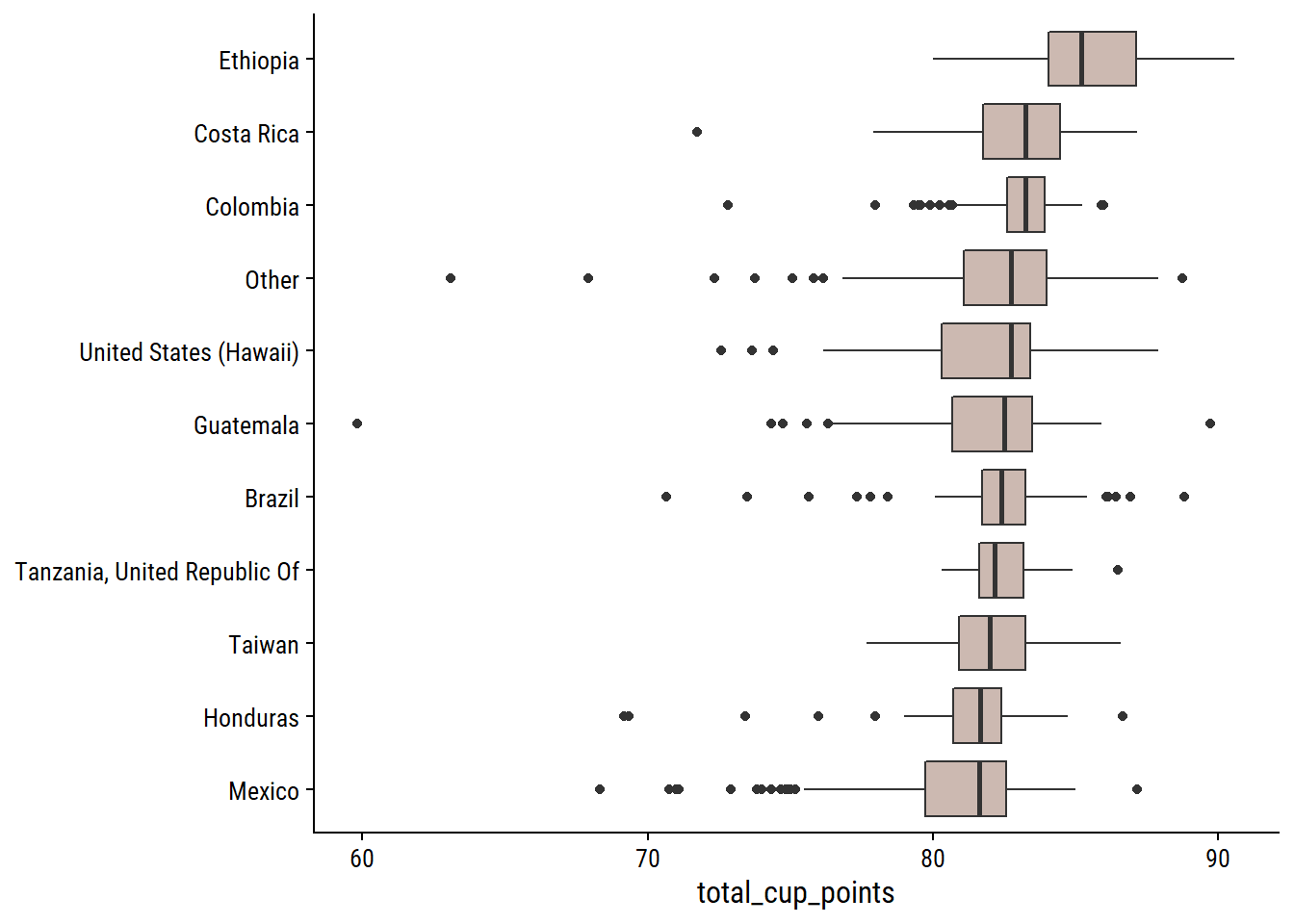
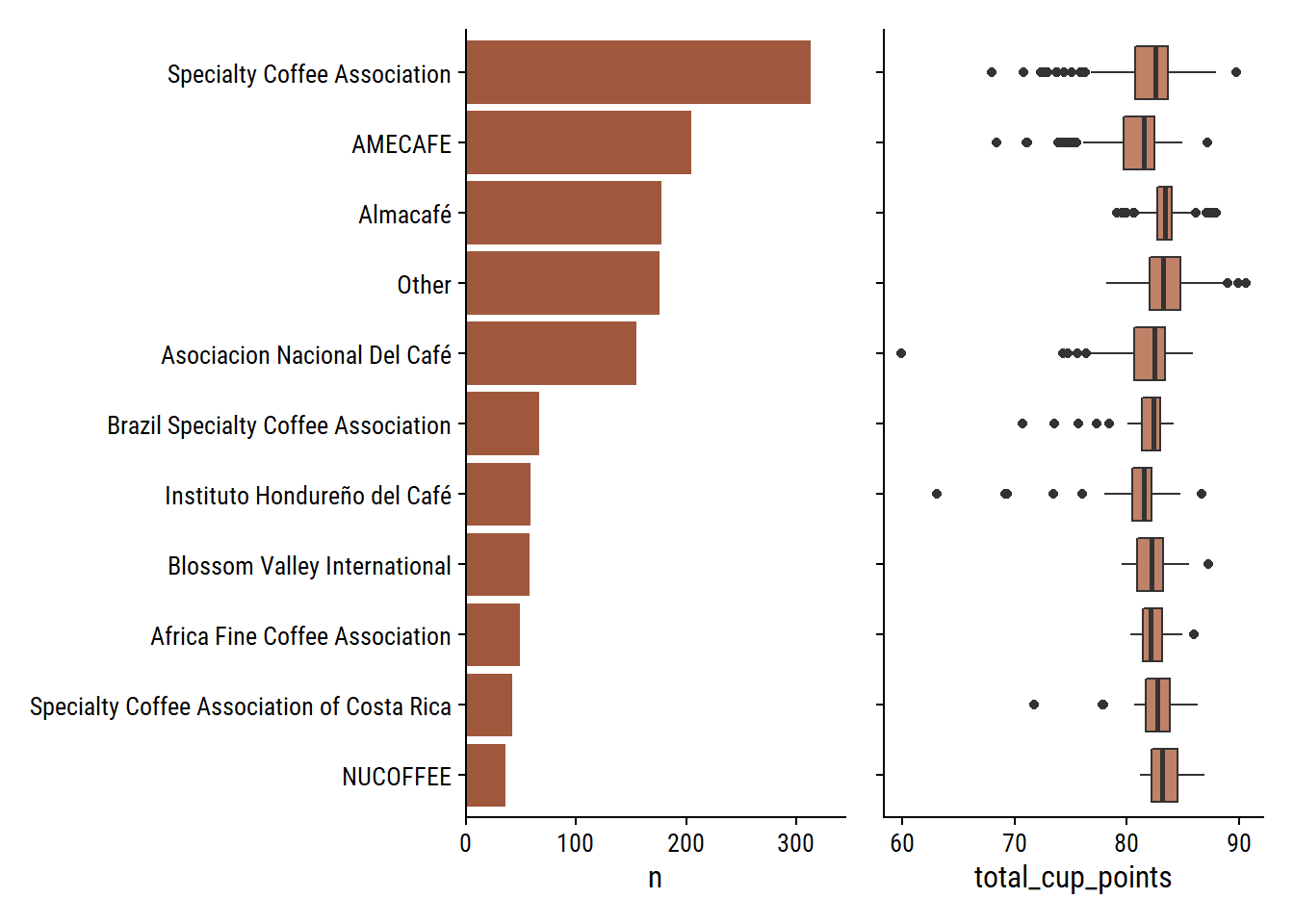
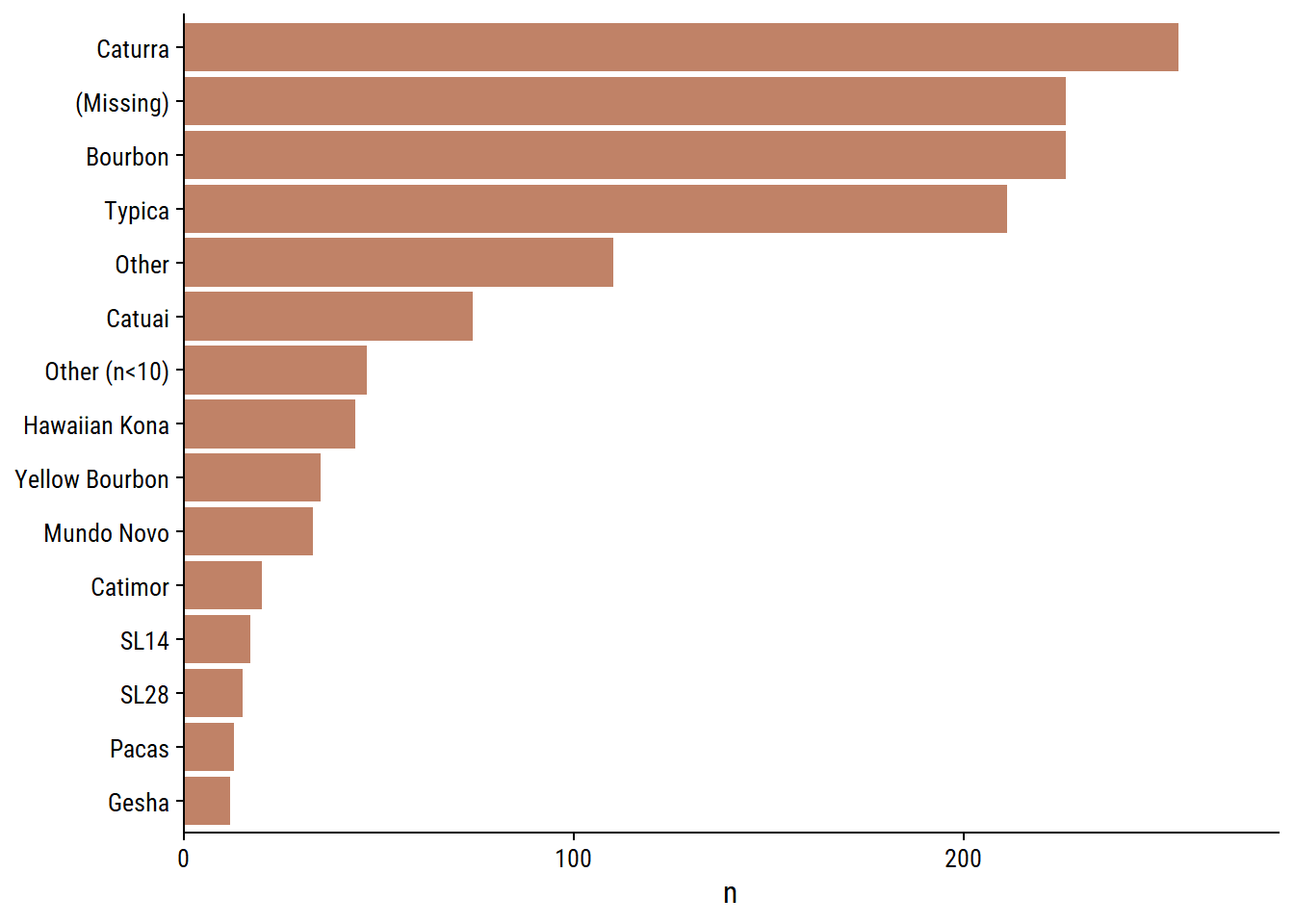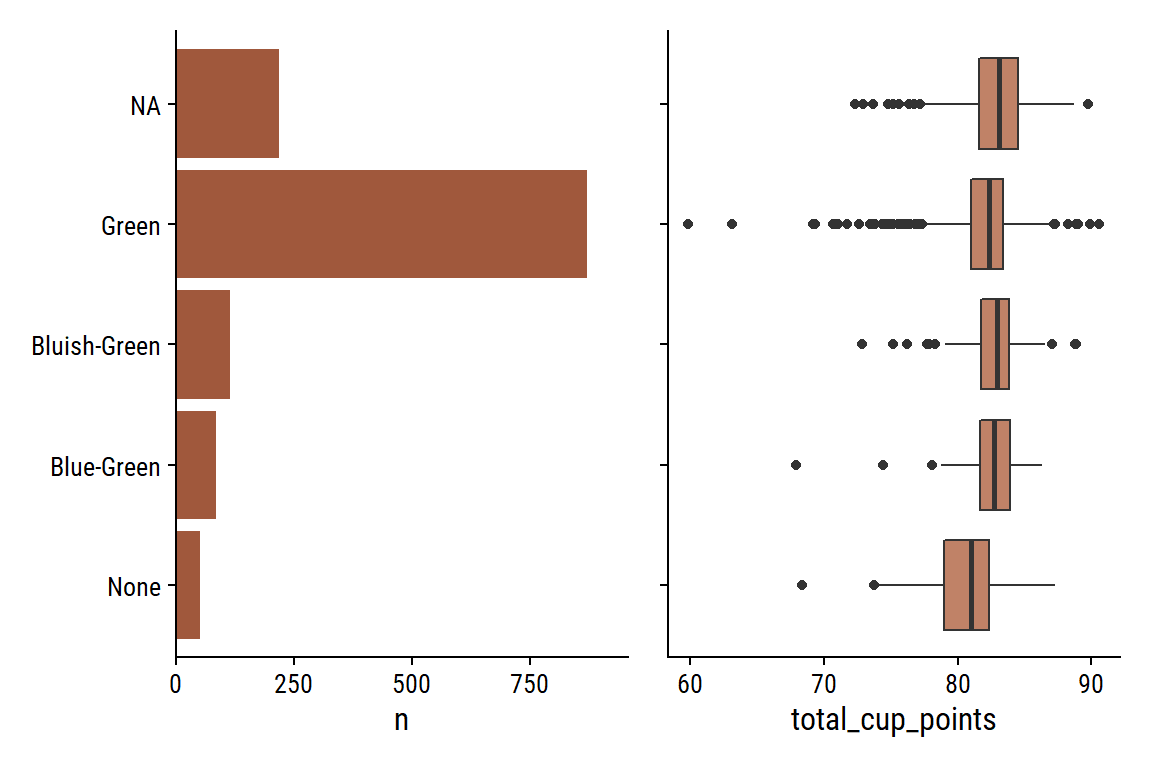What is the relationship between the individual gradings and the overall total_cup_points? There are 10 gradings with scores 0-10, so I assume adding them together gives total_cup_points, which ranges 0-100:
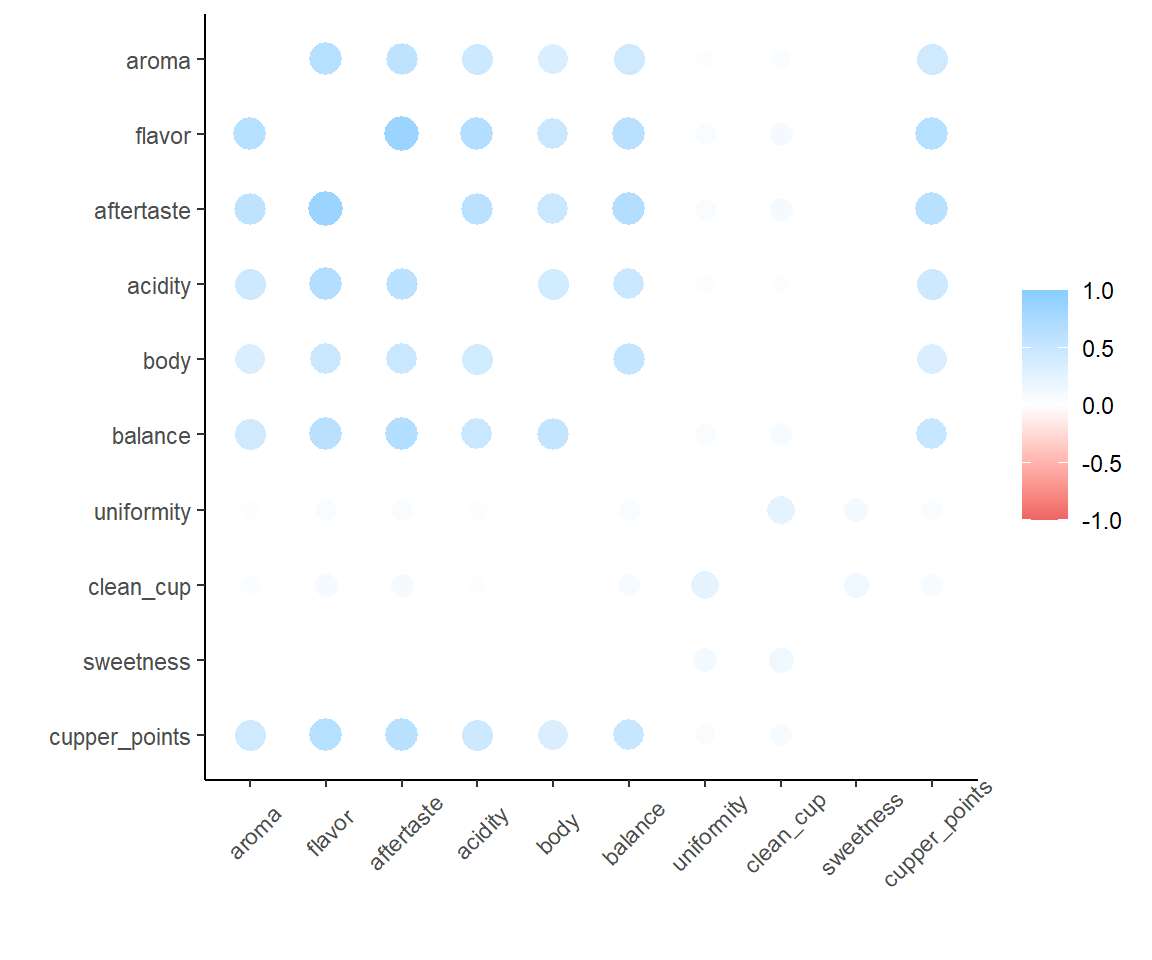
Some very slight deviations, but yes my assumption is correct. A second assumption: there will be mostly positive associations among the individual gradings (e.g. a coffee with high flavor will have high body on average). Compute and plot the pairwise correlations with corrr:
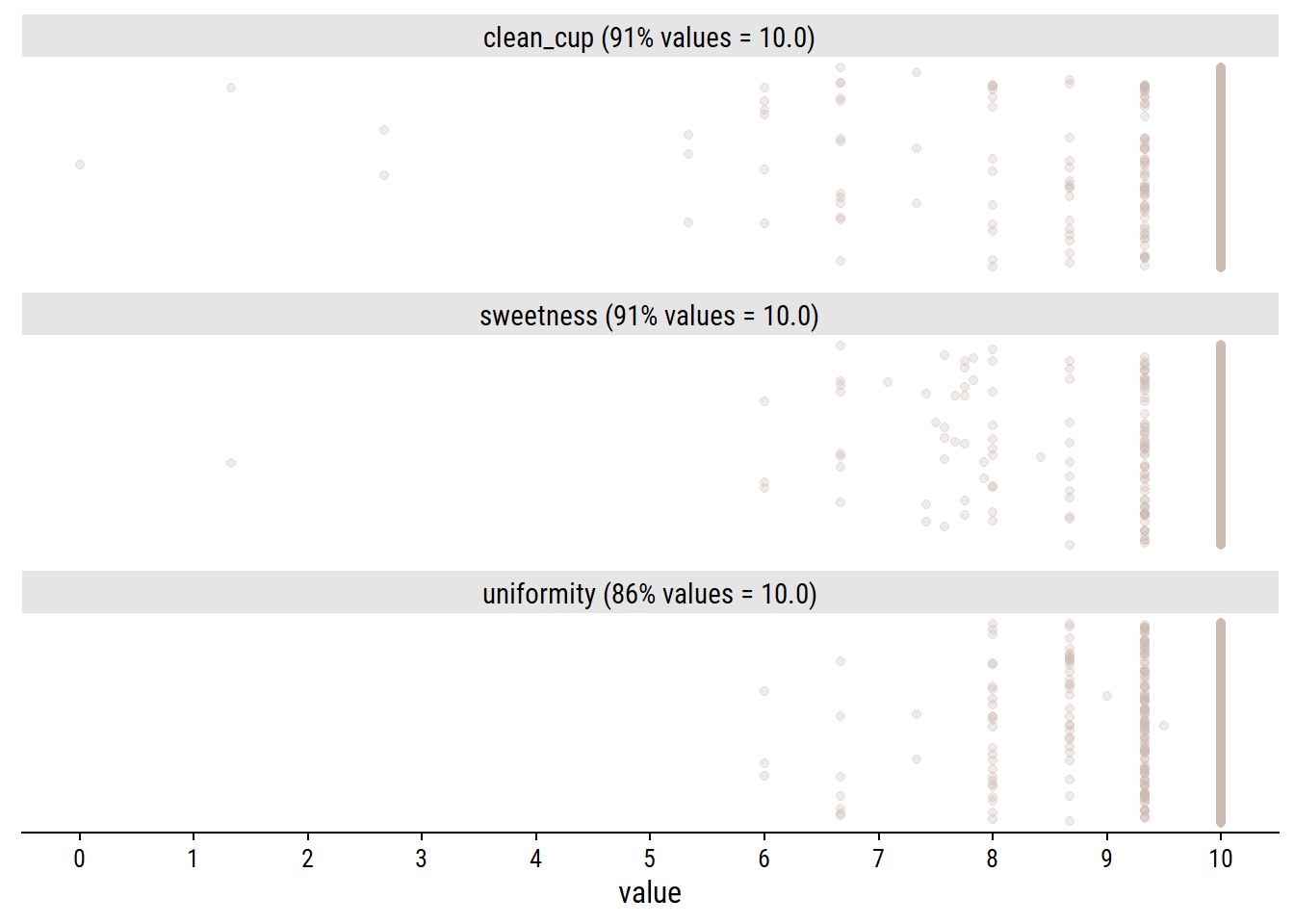
Yes, lots of high correlations. Interestingly, there are three variables in particular (uniformity, clean_cup and sweetness) which correlate moderately with eachother, and weakly with the others. These happen to be the gradings that are almost always 10:
There are two unknown values for variety: “Other” and NA (Missing). These could have different meanings (e.g. an NA value could be a common variety but is just missing) but I will combine both:
It doesn’t work with values like “08/09” because they are not 4 digits, but those values are very low frequency.
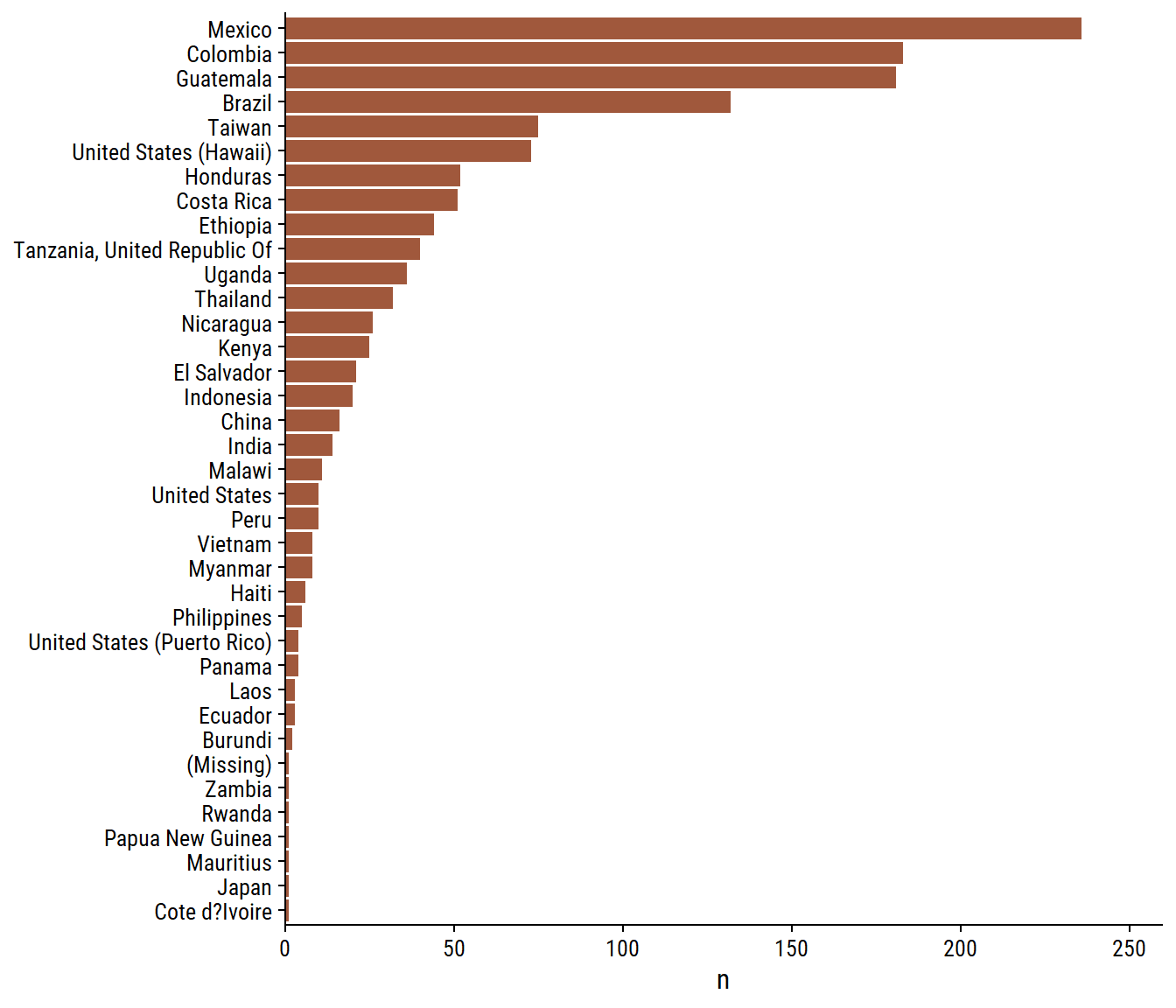
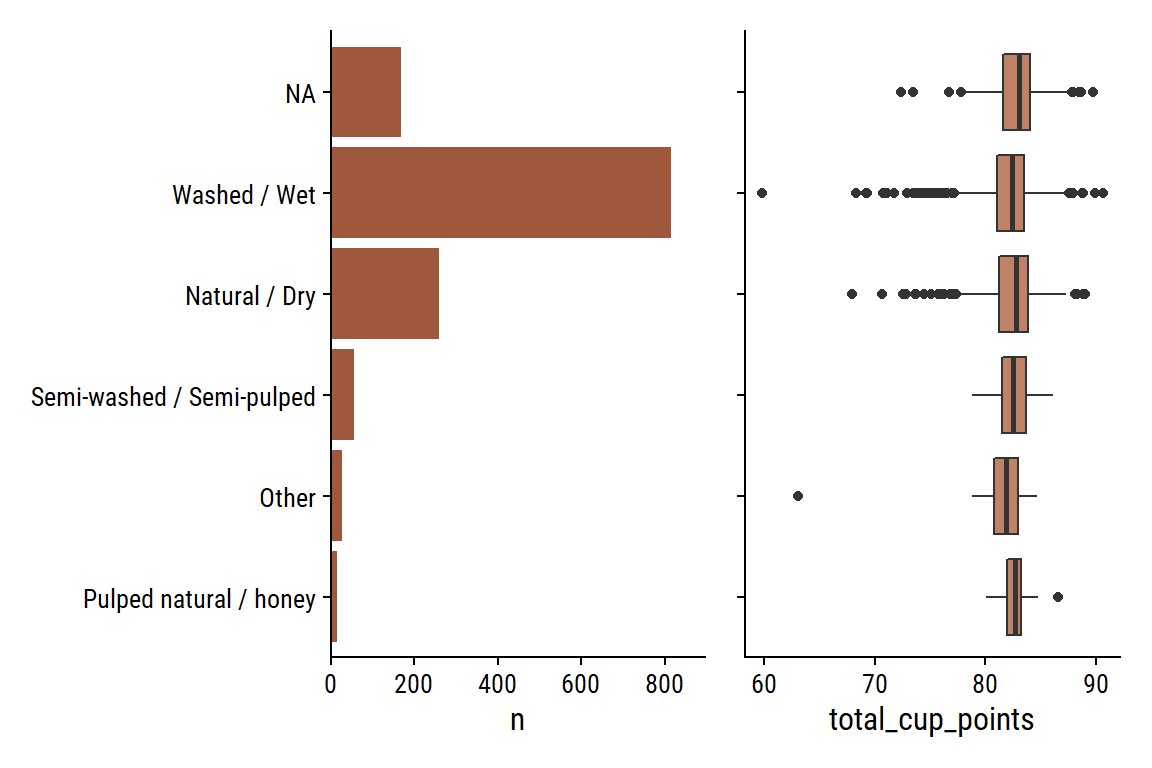
The 5 processing_methods:
d <- coffee %>%add_count(processing_method) %>%mutate(processing_method =fct_reorder(processing_method, n))p1 <- d %>%distinct(processing_method, n) %>%ggplot(aes(y = processing_method, x = n)) +geom_col(fill = coffee_pal[1]) +scale_x_continuous(expand =expansion(mult =c(0, 0.1))) +labs(y =NULL)p2 <- d %>%ggplot(aes(y = processing_method, x = total_cup_points)) +geom_boxplot(fill = coffee_pal[2]) +labs(y =NULL) +theme(axis.text.y =element_blank())p1 | p2
There are two date variables that I think would be interesting to compare: grading_date and expiration. Parse them as date objects and compute the difference in days:
coffee <- coffee %>%mutate(# Convert both to date objectsexpiration = lubridate::mdy(expiration),grading_date = lubridate::mdy(grading_date) )coffee %>%mutate(days_from_expiration = expiration - grading_date ) %>%count(days_from_expiration)
# A tibble: 1 × 2
days_from_expiration n
<drtn> <int>
1 365 days 1338
Every single grading was (supposedly) done 365 days before expiration. Maybe it is standard procedure that gradings be done exactly one year before expiration. Not sure, but this unfortunately makes it an uninteresting variable for exploration/modeling.
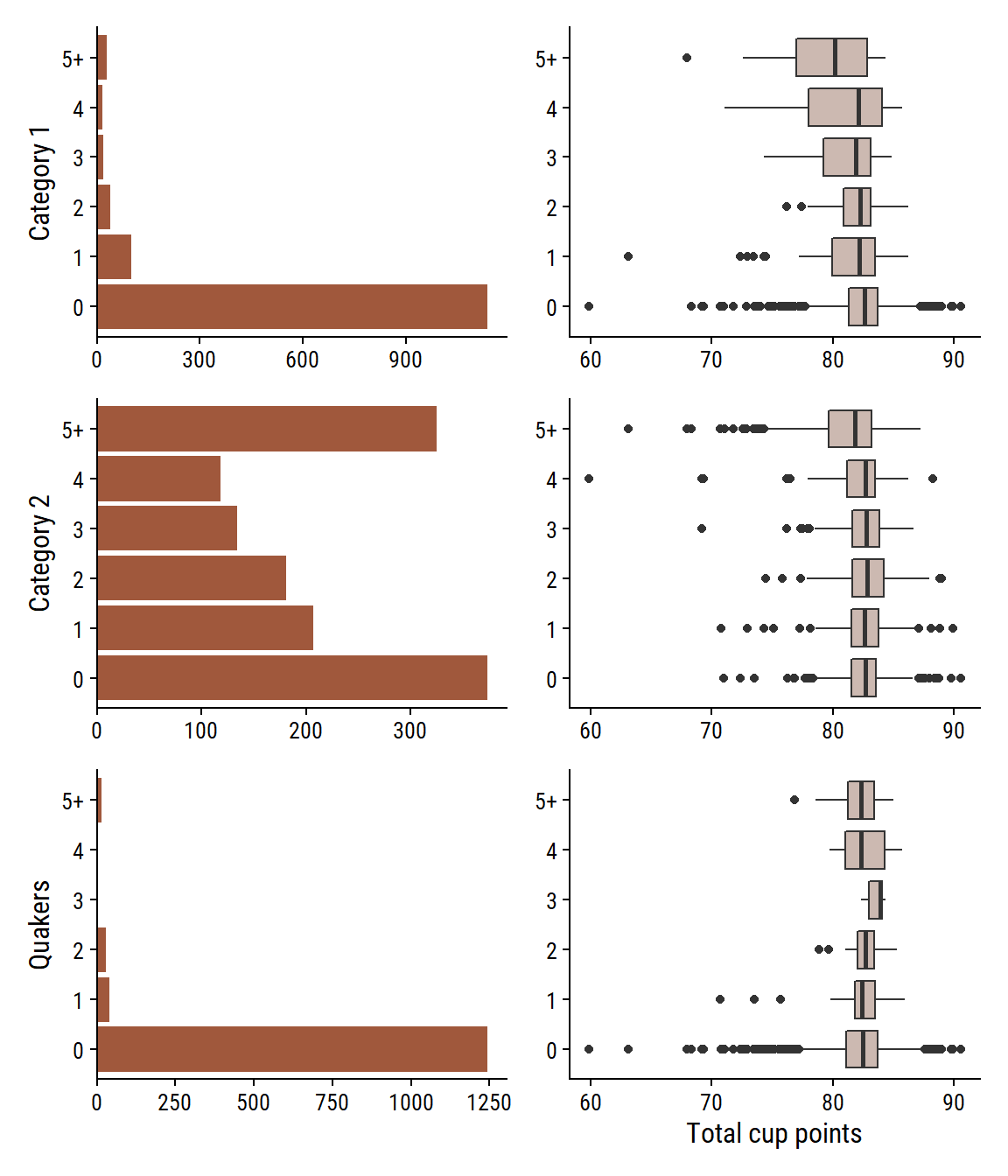
Defects
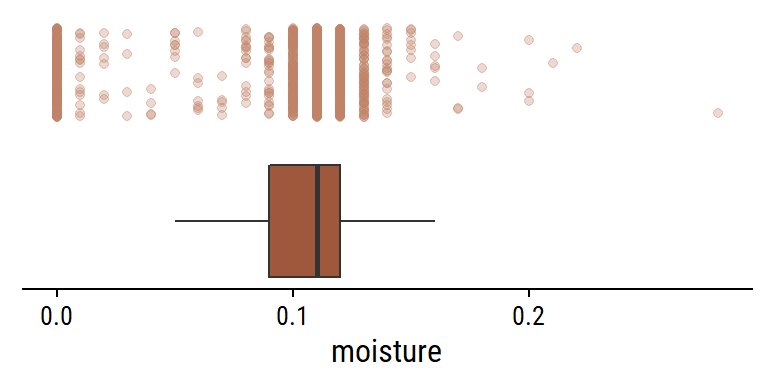
There are two defect variables (category_one_defects and category_two_defects) and the quakers variable, which are immature/unripe beans.
There are some unit conversions from feet to meters, for example:
coffee %>%filter(unit_of_measurement =="ft", !is.na(altitude)) %>%count(altitude, unit_of_measurement, altitude_mean_meters, sort = T) %>%# Re-calculate the altitude in feet to see if it matchesmutate(feet_manual = altitude_mean_meters *3.28) %>%paged_table()
And re-calculating the altitude in feet, everything looks to be correctly converted.
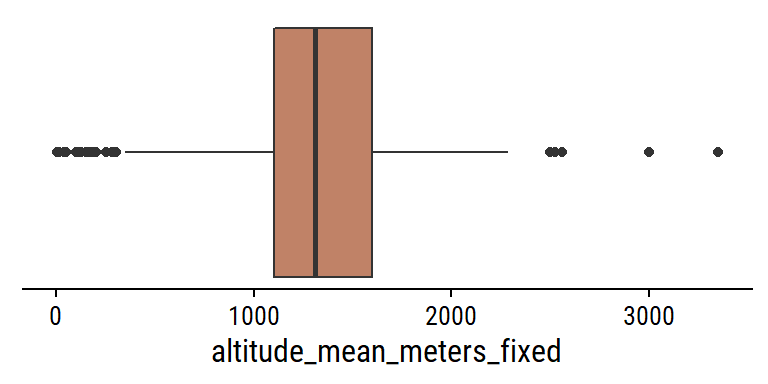
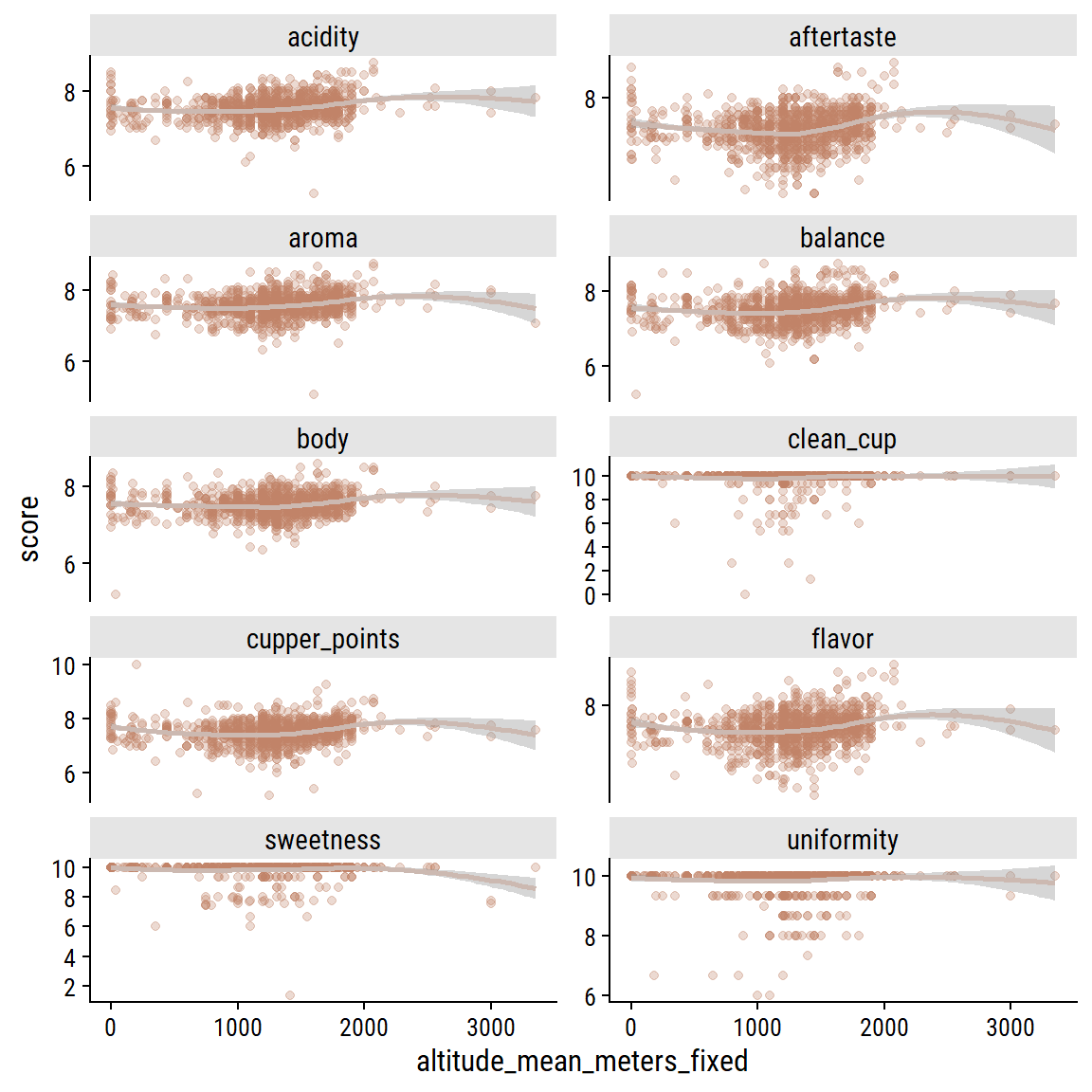
That is looking a bit better. Plot the relationship between the uni-dimensional ratings and mean altitude:
coffee %>%select(aroma:cupper_points, altitude_mean_meters_fixed) %>%filter(!is.na(altitude_mean_meters_fixed)) %>%pivot_longer(cols =-altitude_mean_meters_fixed,names_to ="grading", values_to ="score") %>%ggplot(aes(x = altitude_mean_meters_fixed, y = score)) +geom_point(alpha =0.3, color = coffee_pal[2]) +geom_smooth(method ="loess", formula ="y ~ x", color = coffee_pal[3]) +facet_wrap(~grading, ncol =2, scales ="free_y") +scale_y_continuous(breaks =seq(0, 10, 2))
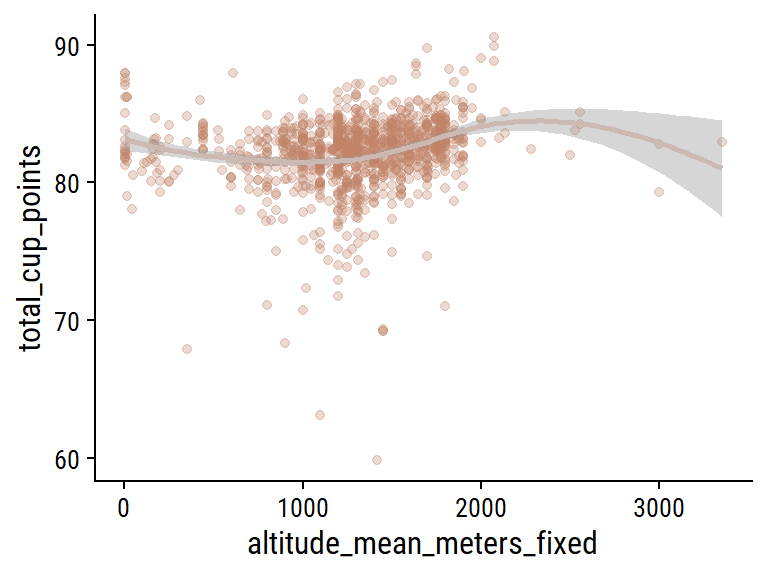
The ratings are so clustered around the 6-9 range, it is hard to see much of a relationship but there does seem to be a small bump in ratings around 1500-2000 meters for a few of the variables. Can we see it in total scores?
coffee %>%filter(!is.na(altitude_mean_meters_fixed)) %>%ggplot(aes(x = altitude_mean_meters_fixed, y = total_cup_points)) +geom_point(alpha =0.3, color = coffee_pal[2]) +geom_smooth(method ="loess", formula ="y ~ x", color = coffee_pal[3]) +scale_y_continuous(breaks =seq(0, 100, 10))
Yes, there looks to be the range of altitudes with the highest ratings on average.
Model
I want to attempt to predict scores for one of the individual gradings (not the 0-100 total score, or the three that are mostly 10s), which I will choose randomly:
Load tidymodels, split the data 3:1 into training and testing (stratified by the outcome flavor), and define the resampling strategy:
# Some minor pre-processingcoffee <- coffee %>%mutate(variety =fct_explicit_na(variety),across(where(is.character), factor) )library(tidymodels)set.seed(42)coffee_split <-initial_split(coffee, prop =3/4, strata = flavor)coffee_train <-training(coffee_split)coffee_test <-testing(coffee_split)coffee_resamples <-vfold_cv(coffee_train, v =5, strata = flavor)
Now define the recipe:
Impute the mode for missing categorical values
Lump together categorical values with <5% frequency
Impute the mean for missing numerical values
Standardize all numerical predictors (important for lasso regularization)
Given its non-linear relationship, use splines in the altitude_mean_meters_fixed predictor
coffee_rec <-recipe( flavor ~ species + country_of_origin + processing_method + color + in_country_partner + variety + aroma + aftertaste + acidity + body + balance + uniformity + clean_cup + sweetness + cupper_points + moisture + category_one_defects + category_two_defects + quakers + altitude_mean_meters_fixed,data = coffee_train ) %>%# Where missing, impute categorical variables with the most common valuestep_impute_mode(all_nominal_predictors()) %>%# Some of these categorical variables have too many levels, group levels# with <5% frequency step_other(country_of_origin, variety, in_country_partner, processing_method,threshold =0.05) %>%# These two numerical predictors have some missing value, so impute with meanstep_impute_mean(quakers, altitude_mean_meters_fixed) %>%# Normalize (0 mean, 1 SD) all numerical predictorsstep_normalize(all_numeric_predictors()) %>%# Use splines in the altitude variable to capture it's non-linearity.step_ns(altitude_mean_meters_fixed, deg_free =4) %>%# Finally, create the dummy variables (note that this step must come *after*# normalizing numerical variables)step_dummy(all_nominal_predictors())coffee_rec
Recipe
Inputs:
role #variables
outcome 1
predictor 20
Operations:
Mode imputation for all_nominal_predictors()
Collapsing factor levels for country_of_origin, variety, in_country_partner,...
Mean imputation for quakers, altitude_mean_meters_fixed
Centering and scaling for all_numeric_predictors()
Natural splines on altitude_mean_meters_fixed
Dummy variables from all_nominal_predictors()
Before applying the recipe, we can explore the processing steps with the recipes::prep() and recipes::bake() functions applied to the training data:
And before fitting any models, register parallel computing to speed up the tuning process:
# Speed up the tuning with parallel processingn_cores <- parallel::detectCores(logical =FALSE)library(doParallel)cl <-makePSOCKcluster(n_cores -1)registerDoParallel(cl)
Linear regression
Start simple, with just a linear regression model:
Linear regression does great, which makes me think that the more complicated models to follow will be overkill.
Lasso regression
We will tune (i.e. allow the penalty term \(\lambda\) to vary) a lasso regression model to see if it can outperform a basic linear regression:
lasso_spec <-linear_reg(penalty =tune(), mixture =1) %>%set_engine("glmnet")# Define the lambda values to try when tuninglasso_lambda_grid <-grid_regular(penalty(), levels =50)lasso_workflow <-workflow() %>%add_recipe(coffee_rec) %>%add_model(lasso_spec)library(tictoc) # A convenient package for timingtic()lasso_tune <-tune_grid( lasso_workflow,resamples = coffee_resamples,grid = lasso_lambda_grid )toc()
1.69 sec elapsed
show_best(lasso_tune, metric ="rmse")
# A tibble: 5 × 7
penalty .metric .estimator mean n std_err .config
<dbl> <chr> <chr> <dbl> <int> <dbl> <chr>
1 0.00356 rmse standard 0.149 5 0.00417 Preprocessor1_Model38
2 0.00222 rmse standard 0.149 5 0.00417 Preprocessor1_Model37
3 0.00569 rmse standard 0.149 5 0.00427 Preprocessor1_Model39
4 0.00139 rmse standard 0.149 5 0.00416 Preprocessor1_Model36
5 0.000869 rmse standard 0.149 5 0.00414 Preprocessor1_Model35
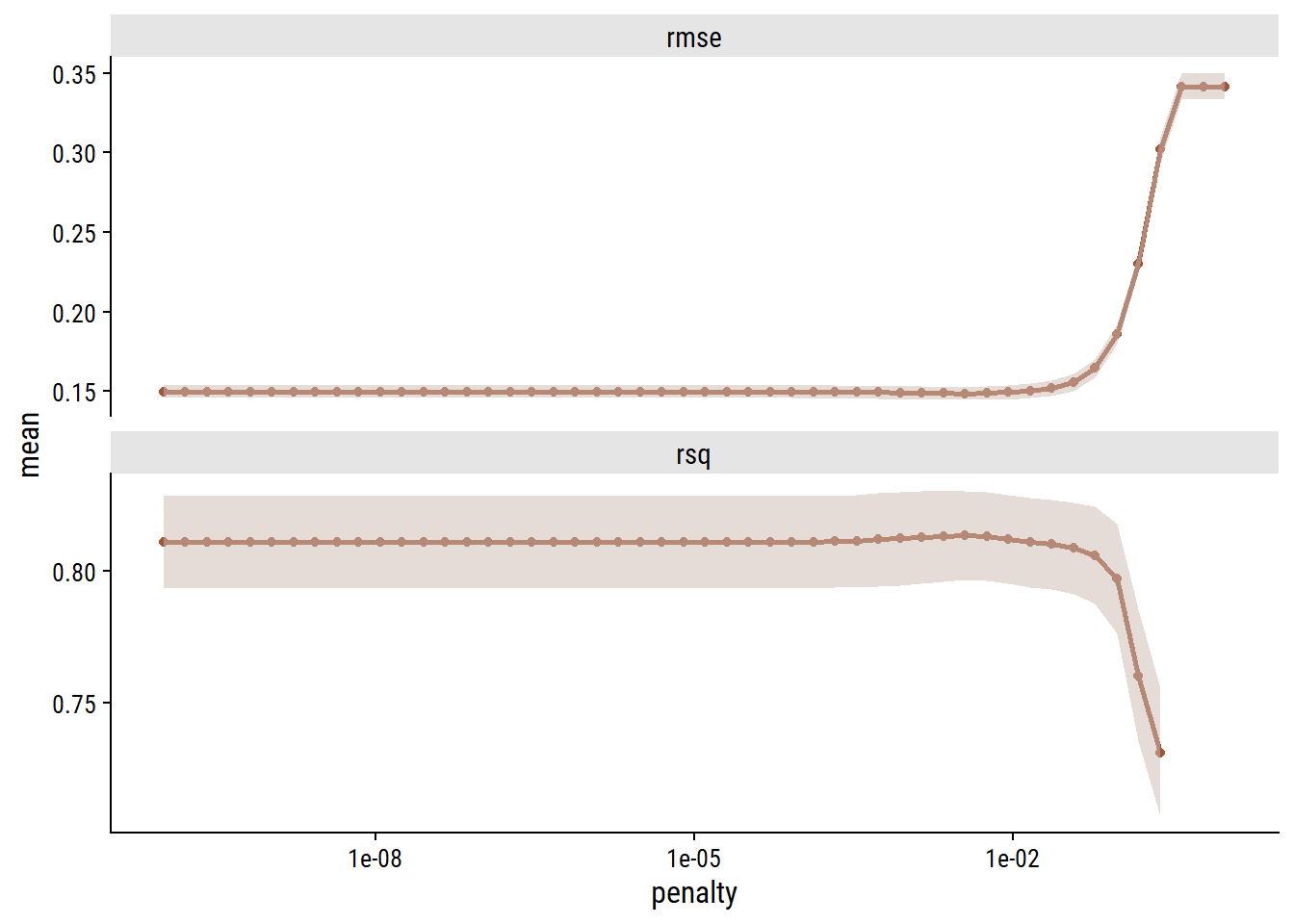
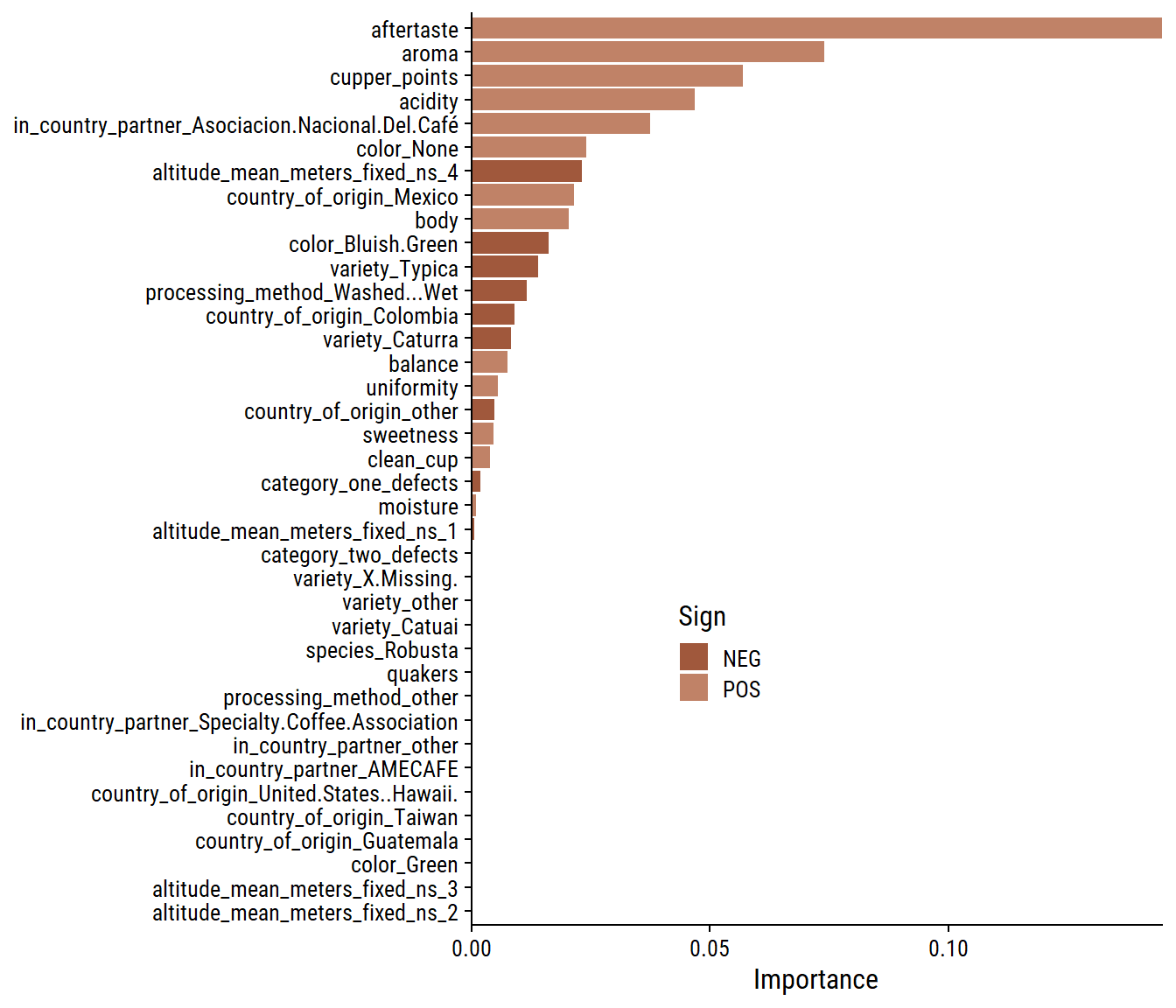
Lasso regression was un-needed in this case, as it did not perform differently than basic linear regression. We can see this by looking at the behaviour of the metrics with \(\lambda\):
collect_metrics(lasso_tune) %>%ggplot(aes(x = penalty, y = mean)) +geom_line(size =1, color = coffee_pal[1]) +geom_point(color = coffee_pal[1]) +geom_ribbon(aes(ymin = mean - std_err, ymax = mean + std_err),alpha =0.5, fill = coffee_pal[3]) +facet_wrap(~.metric, ncol =1, scales ="free_y") +scale_x_log10()
Lower levels of regularization gave better metrics. Regardless, finalize the workflow.
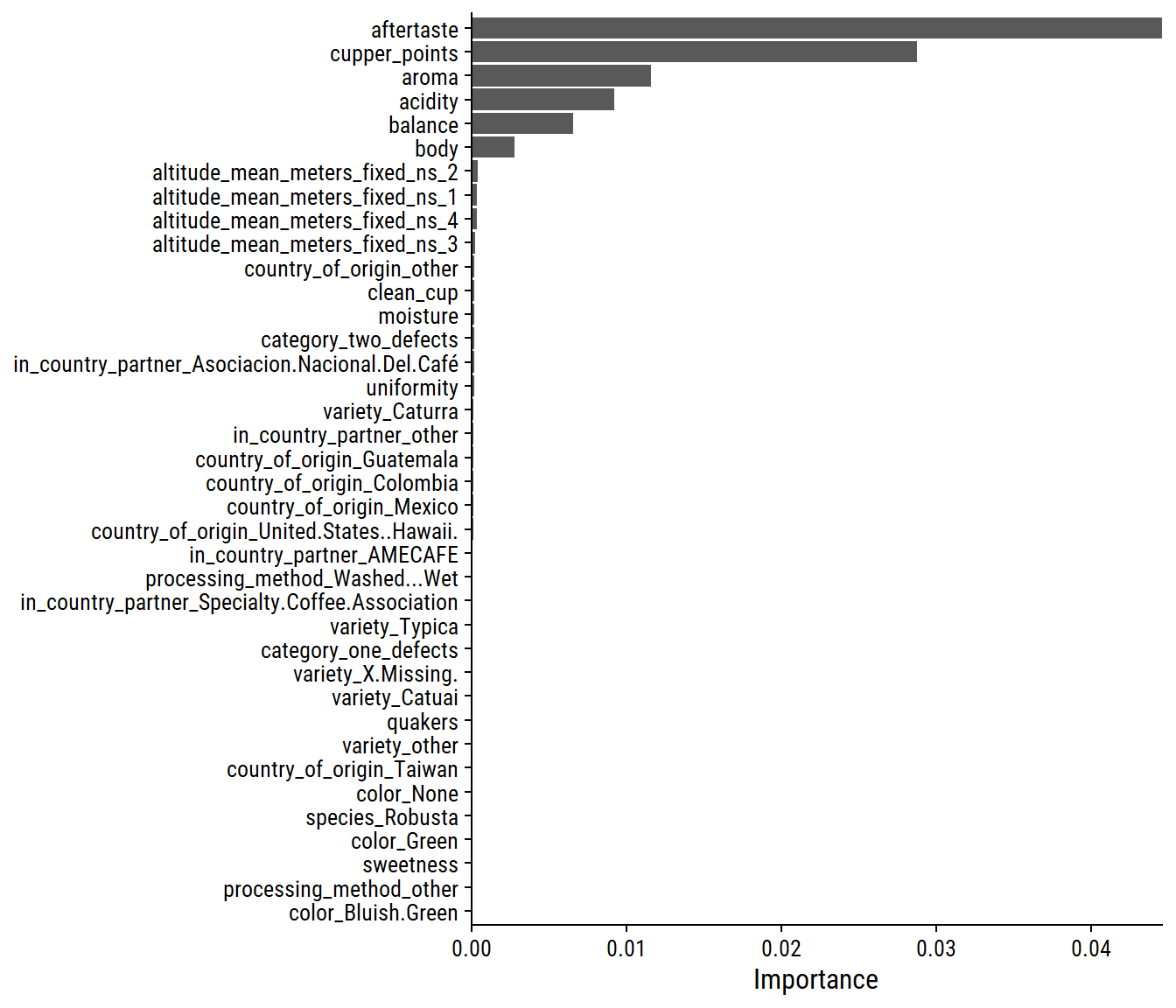
Even fewer variables were deemed important in this model compared to lasso.
Conclusion
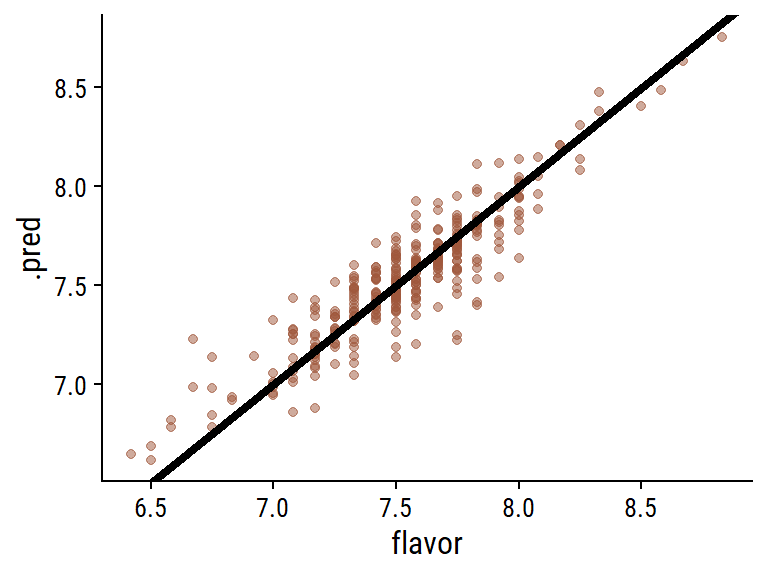
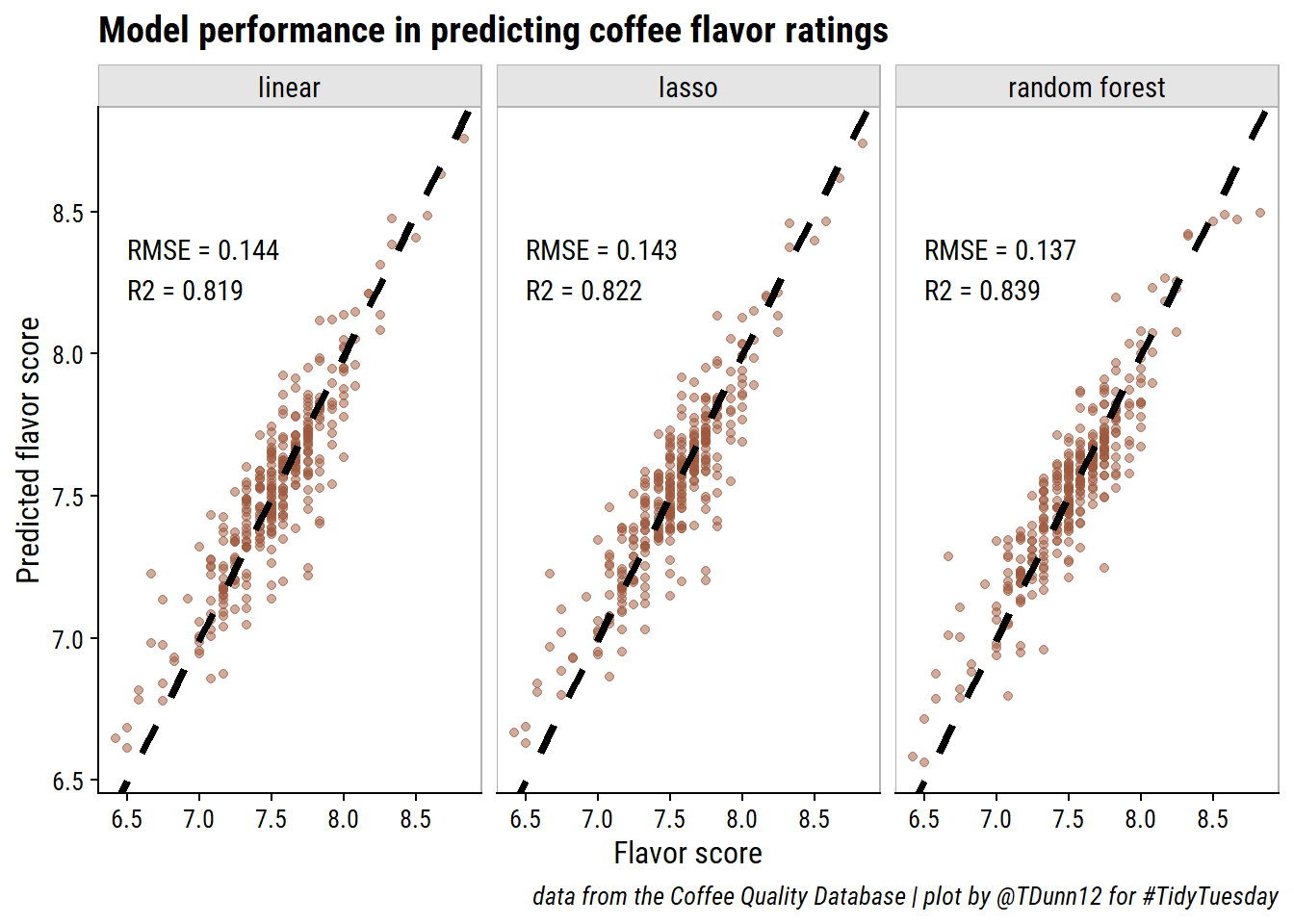
The random forest model was very slightly better in predicting coffee flavor, which I’ll summarize with a plot:
d <-bind_rows(mutate(collect_metrics(lm_fit), fit ="linear"),mutate(collect_metrics(lasso_fit), fit ="lasso"),mutate(collect_metrics(ranger_fit), fit ="random forest")) %>%group_by(fit) %>%summarise(fit_metrics = glue::glue("RMSE = {round(.estimate[.metric == 'rmse'], 3)}\n","R2 = {round(.estimate[.metric == 'rsq'], 3)}" ),.groups ="drop" ) %>%left_join(bind_rows(mutate(collect_predictions(lm_fit), fit ="linear"),mutate(collect_predictions(lasso_fit), fit ="lasso"),mutate(collect_predictions(ranger_fit), fit ="random forest") ),by ="fit" ) %>%mutate(fit =factor(fit, levels =c("linear", "lasso", "random forest")))
d %>%ggplot(aes(x = flavor, y = .pred)) +geom_point(color = coffee_pal[1], alpha =0.5) +geom_abline(slope =1, intercept =0, size =1.5, lty =2) +geom_text(data = . %>%distinct(fit, fit_metrics),aes(label = fit_metrics, x =6.5, y =8.3), hjust =0) +facet_wrap(~fit, nrow =1) +add_facet_borders() +labs(y ="Predicted flavor score", x ="Flavor score",title ="Model performance in predicting coffee flavor ratings",caption =paste0("data from the Coffee Quality Database | ","plot by @TDunn12 for #TidyTuesday"))
Reproducibility
Session info
setting value
version R version 4.2.1 (2022-06-23 ucrt)
os Windows 10 x64 (build 19044)
system x86_64, mingw32
ui RTerm
language (EN)
collate English_Canada.utf8
ctype English_Canada.utf8
tz America/Curacao
date 2022-10-27
pandoc 2.18 @ C:/Program Files/RStudio/bin/quarto/bin/tools/ (via rmarkdown)
Git repository
Local: main C:/Users/tdunn/Documents/tdunn-quarto
Remote: main @ origin (https://github.com/taylordunn/tdunn-quarto.git)
Head: [4eb5bf2] 2022-10-26: Added font import to style sheet